When ensuring high availability for SAP ASCS and ERS running on WIndows Server, the primary cluster solution you will want to use is Windows Server Failover Clustering. However, when doing this in AWS you will quickly discover that there are a few obstacles you need to know how to overcome when deploying this in AWS.
I recently wrote this Step-by-Step guide that was published on the SAP blog that walks you through the entire process. If you have any questions, please leave a comment.
AWS
Using Amazon FSx for SQL Server Failover Cluster Instances – What You Need to Know!
Intro
If you are considering deploying your own Microsoft SQL Server instances in AWS EC2 you have some decisions to make regarding the resiliency of the solution. Sure, AWS will offer you a 99.99% SLA on your Compute resources if you deploy two or more instances across different availability zones. But don’t be fooled, there are a lot of other factors you need to consider when calculating your true application availability. I recently blogged about how to calculate your application availability in the cloud. You probably should have a quick read of that article before you move on.
When it comes to ensuring your Microsoft SQL Server instance is highly available, it really comes down to two basic choices: Always On Availability Group (AG) or SQL Server Failover Cluster Instance (FCI). If you are reading this article I’m making an assumption you are well aware of both of these options and are seriously considering using a SQL Server FCI instead of a SQL Server Always On AG.
Benefits of a Microsoft SQL Server Failover Cluster Instance
The following list summarize what AWS says are the benefits of a SQL Server FCI:
FCI is generally preferable over AG for SQL Server high availability deployments when the following are priority concerns for your use case:
License cost efficiency: You need the Enterprise Edition license of SQL Server to run AGs, whereas you only need the Standard Edition license to run FCIs. This is typically 50–60% less expensive than the Enterprise Edition. Although you can run a Basic version of AGs on Standard Edition starting from SQL Server 2016, it carries the limitation of supporting only one database per AG. This can become a challenge when dealing with applications that require multiple databases like SharePoint.
Instance-level protection versus database-level protection: With FCI, the entire instance is protected – if the primary node becomes unavailable, the entire instance is moved to the standby node. This takes care of the SQL Server logins, SQL Server Agent jobs, certificates, etc. that are stored in the system databases, which are physically stored in shared storage. With AG, on the other hand, only the databases in the group are protected, and system databases cannot be added to an AG – only user databases are allowed. It is the database administrator’s responsibility to replicate changes to system objects on all AG replicas. This leaves the possibility of human error causing the database to become inaccessible to the application.
DTC feature support: If you’re using SQL Server 2012 or 2014, and your application uses Distributed Transaction Coordinator (DTC), you are not able to use an AG as it is not supported. Use FCI in this situation.
Challenges with FCI in the Cloud
Of course, the challenge with building an FCI that spans availability zones is the lack of a shared storage device that is normally required when building a SQL Server FCI. Because the nodes of the cluster are distributed across multiple datacenters, a traditional SAN is not a viable option for shared storage. That leaves us with a two choices for cluster storage: 3rd party storage class resources like SIOS DataKeeper or the new Amazon FSx. Let’s take a look at what you need to know before you make your choice.
Service Level Agreement
As I wrote in how to calculate your application availability, your overall application SLA is only as good as your weakest link. In this case, the FSx SLA of 99.9%.
Normally 99.99% availability represents the starting point of what is considered “highly available”. This is what AWS promises you for your compute resources when two or more are deployed in different availability zones.
In case you didn’t know the difference between three nines and four nines…
- 99.9% availability allows for 43.83 minutes of downtime per month
- 99.99% availability allows for only 4.38 minutes of downtime per month
By hosting your cluster storage on FSx despite your 99.99% compute availability, your overall application availability will be 99.9%. In contrast, EBS volumes that span availability zones, such as in a DataKeeper deployment, qualifies for the 99.99% SLA at both the storage and compute layers, meaning your overall application availability is 99.99%.
Storage Location
When configuring FSx for high availability, you will want to enable multi-AZ support. By enabling multi-AZ you have an effectively have a “preferred” AZ and a “standby” AZ. When you deploy your SQL Server FCI nodes you will want to distribute those nodes across the same AZs.
Now in normal situations, you will want to make sure the active cluster node resides in the same AZ as the preferred FSx storage node. This is to minimize the distance and latency to your storage, but also to minimize the costs associated with data transfer across AZs. As specified in the FSx price guide, “Standard data transfer fees apply for inter-AZ or inter-region access to file systems.”
In the unfortunate circumstance where you have a SQL Server FCI failure, but not a FSx failure, there is no mechanism to tie both the storage and compute together. In the event that FSx fails over, it will automatically fail back to the primary availability zone. However, best practices dictate SQL FCI remain running on the secondary node until root cause analysis is performed and fail back is typically scheduled to occur during maintenance periods. This leaves you in a situation where your storage resides in a different AZ, which will incur additional costs. Currently the cost for transferring data across AZs, both ingress and egress, is $0.01/GB.
Without keeping a close eye on the state of your FSx and SQL Server FCI, you may not even be aware that they are running in different regions until you see the data transfer charge at the end of the month.
In contrast, in a configuration that use SIOS DataKeeper, the storage failover is part of the SQL Server FCI recovery, ensuring that the storage always fails over with the SQL Server instance. This ensures SQL Server is always reading and writing to the EBS volumes that are directly attached to the active node. Keep in mind, DataKeeper will incur a data transfer cost associated with write operations which are replicated between AZs or regions. This data transfer cost can be minimized with the use of compression available in DataKeeper.
Controlling Failover
In an FSx multi-subnet configuration there is a preferred availability zone and a standby availability. Should the FSx file server in the preferred availability zone experience a failure, the file server in the standby AZ will recover. AWS reports that this recovery time takes about 30 seconds with standard shares. With the use of continuously available file shares Microsoft reports this failover time can be closer to 15 seconds. During this failover time, there is a brownout that occurs where reads and writes are paused, but will continue once recovery completes.
FSx multi-site has automatic failback enabled, meaning that for every unplanned failover of FSx, you also have an unplanned failback. In contrast, typically when a SQL Server FCI experience an unplanned failover you would either just leave it running on the secondary or schedule a failback after hours or during the next maintenance period.
SQL Server Analysis Services Cluster Not Supported with FSx
If you want to cluster SSAS, you will need a clustered disk resource like SIOS DataKeeper. The How to Cluster SQL Server Analysis Server white paper clearly states that SMB cannot be used and that cluster drives with drive letters must be used. In contrast, the DataKeeper Volume resource presents itself as a clustered disk and can be used with SSAS.
Summary
While FSx certainly can make sense for typical SMB uses like Windows user files and other non-critical services where 99.9% availability SLA suffices, FSx is an excellent option If you application requires high availability (99.99%) or HA/DR solutions that also span regions, the SIOS DataKeeper is the right fit.
Calculating Application Availability in the Cloud
When deploying business critical applications in the cloud you want to make sure they are highly available. The good news is that if you plan properly, you can achieve 99.99% (4-nines) of availability or more. However, calculating your true availability may not be as straightforward as it seems.
When considering availability you must consider the key components that make access to your application possible, which I’ll call the availability chain. Component of the availability chain are:
- Compute
- Network
- Storage
- Application
- Dependent services
Your application is only as available as your weakest link, and your downtime increases exponentially with each additional link you add to the chain. Let’s examine each of the links.
Compute Availability
Each of the three major cloud service providers have some similarities. One thing in common across all three platforms is the service level agreements (SLA) they will commit to for compute.
The SLA for all three public cloud providers for VMs when you have two or more VMs configured across different availability zones is 99.99%. Keep in mind, this SLA only guarantees the remote accessibility of one of the VMs at any given time, it makes no promises as to the availability of the services or application(s) running inside the VM. If you deploy a single VM within a single datacenter, this SLA varies from “90% of each hour” (AWS) to 99.5% (Azure and GCP) or 99.9% (Azure single VM when using Premium SSD).
True high availability starts at 99.99%, so the first step is to ensure your application is available is to make sure the application is distributed across two or more VMs that span availability zones. With two VMs spread across two availability zones, giving you 99.99% availability of at least one of those VMs, you could theorize that if you had three VMs spread across three availability zones your availability would be even greater than 99.99%. Although the cloud providers’ SLA will never guarantee beyond 99.99% availability regardless of the number of availability zones in use, if you use pure statistics you might come to the conclusion that your availability could jump to as high as 99.999999% or 8-nines of availability, 26.30 milliseconds downtime per month.
1-(.0001*.0001) = .99999999
99.999999% availability with three availability zones?
Don’t go around quoting that number, but just keep in mind that it makes sense that if two availability zones can give you 99.99% availability, it stands to reason that three availability zones is going to give you something significantly more than 99.99% availability.
Compute is just one link in the availability chain. We still have to address network, storage and other dependent services, which all represent possible points of failure.
Network Availability
In order for your application to be available, every network hop between the client and the application and all the resources that the application depends on, must be available and working within tolerable latency ranges. You need to understand the network links between database servers, application servers, web servers and clients to know precisely where the network might fail. And remember, the more links in your availability chain the lower your overall availability will be.
Although network availability betweens VMs in the same vNet are covered under the standard compute SLA, there are other network services that you may be utilizing. Here are just a few examples of network services you could be utilizing which would impact overall application availability.
Express Route – 99.95%
VPN Gateway – 99.9% through 99.95%
Load Balancer – 99.99%
Traffic Manager – 99.99%
Elastic Load Balancer – 99.99%
Direct Connect – 99.9% – 99.99%
Building on what we have learned so far, let’s take a look at the availability of an application that is deployed across two availability zones.
99.99% compute availability
99.99% load balancer availability
.9999 * .9999 = .9998
99.98% availability = ~9 minutes downtime per month
Now that we have addressed compute and network availability, let’s move on to storage.
Storage Availability
Now here is where the story gets a little hairy. Have a look at the following storage SLAs
https://azure.microsoft.com/en-us/support/legal/sla/storage/v1_5/
https://cloud.google.com/storage/sla
https://aws.amazon.com/compute/sla/
It seems pretty clear that Azure and Google are giving you a 99.9% SLA on block storage solutions. AWS doesn’t mention EBS specifically here. They only talk about VMs and measure their single instance VMs availability by the hour instead of by the month as the other cloud providers do. For sake of discussion, lets use the 99.9% availability guarantee that both Azure and GCP have published.
Building upon our previous example, let’s add some storage to the equation.
99.99% compute availability
99.99% load balancer availability
99.9% managed disk
.9999 * .9999 * .999 = .9988
99.88% availability = ~53 minutes of downtime per month.
53 minutes of downtime is a lot more than the 9 minutes of downtime we calculated in our previous example. What can we do to minimize the impact of the 99.9% storage availability? We have to build more redundancy in the storage!
Fortunately, we usually include storage redundancy when planning for application availability. For instance, when we stand up web servers, each web server will typically store data on the locally attached disk. When deploying domain controllers, Microsoft Active Directory takes care of replicating AD information across all the domain controllers. In the case of something like SQL Server, we leverage things Always On Availability Groups or SIOS DataKeeper to keep the data in sync across locally attached disks.
The more copies of the data we have distributed across different availability zones, the more likely we will be able to survive a failure.
For example, an application that stores its data across two different disks in different availability zones will benefit from the redundancy and instead of 99.9% availability it is more likely to achieve 99.9999% availability of the storage.
1 – (.001 * .001) = .999999
If we throw that into the previous equation the picture starts to look a little brighter.
.9999 * .9999 * .999999 = .9998
99.98% availability = ~9 minutes of downtime
By duplicating the data across multiple AZs, and therefore multiple disks, we have effectively mitigated the downtime associated with cloud storage.
Application and Dependent Services Availability
You’ve done all you can do to ensure compute, network, and storage availability. But what about the application itself? Some applications can scale out and provide redundancy by load balancing between multiple instances of the same application. Think of your typical web server farm where you may typically load balance web requests between five servers. If you lose one server the load balancer simply removes it from it’s rotation until it is once again responsive.
Other applications require a little more care and monitoring. Take SQL Server for instance. Typically Always On Availability Groups or Failover Cluster Instances are used to monitor database availability and take recovery actions should a database become unresponsive due to application or system level failures. While there is no published SLA for SQL Server availability solutions, it is commonly accepted that when configured properly for high availability, a SQL Server can provide 99.99% availability.
You may rely on other cloud based services, like hosted Active Directory, hosted DNS, microservices, or even the availability of the cloud portal itself should all be factored into your overall availability equation.
Summary
Application availability is the sum of all the moving parts. Skimping in just one area can exponentially impact the overall availability of your application. Take your time and investigate all the links in your availability chain for weakness including compute, network, storage, application and dependent services.
In general the numbers presented here are hopefully worst case scenarios and your actual availability should exceed the published SLAs. Do your homework and be wary of any service that can not guarantee 99.99% availability, the typical threshold of what is considered highly available.
Human error and security were not addressed in this article. You can make your application as highly available as possible, but if you have not taken steps to secure your application against external threats and stupid human mistakes then all bets are off when it comes to availability.
Step-by-Step: How to Trigger an Email Alert when a Specific Windows Service Starts or Stops on Windows Server 2016
Introduction
In my last post. Step-by-Step: How to Trigger an Email Alert from a Windows Event that Includes the Event Details using Windows Server 2016, I showed you how to send an email alert based upon specific Windows EventIDs being logged in a Windows Event Log. While that works great for most events it is not ideal if you want to be notified when a specific Windows Service starts or stops.
When a Windows Service starts or stops an EventID 7036 from the Source “Service Control Manager” is logged in the Windows System Log. Now we could simply set up a trigger to send an email whenever that EventID is logged as I described in my previous post, however you might not want to receive an email when EVERY Windows Service starts or stops.
To get a little more specific we will have to edit the XML data associated with the Windows Event Filter when we set up the trigger to look a little deeper at the Event Properties and filter on the EventData that is only shown when you view the XML View on the Details tab of a Windows Event.
This work was verified on Windows Server 2016, but I suspect it should work on Windows Server 2012 R2 and Windows Server 2019 as well. If you get it working on any other platforms please comment and let us know if you had to change anything.
Step 1 – Write a Powershell Script
The first thing that you need to do is write a Powershell script that when run can send an email. While researching this I discovered many ways to accomplish this task, so what I’m about to show you is just one way, but feel free to experiment and use what is right for your environment.
In my lab I do not run my own SMTP server, so I had to write a script that could leverage my Gmail account. You will see in my Powershell script the password to the email account that authenticates to the SMTP server is in plain text. If you are concerned that someone may have access to your script and discover your password then you will want to encrypt your credentials. Gmail requires and SSL connection so your password should be safe on the wire, just like any other email client.
Here is an example of a Powershell script that when used in conjunction with Task Scheduler which will send an email alert automatically when any specified Event is logged in the Windows Event Log. In my environment I saved this script to C:\Alerts\ServiceAlert.ps1
$filter="*[System[EventID=7036] and EventData[Data='SIOS DataKeeper']]"
$A = Get-WinEvent -LogName System -MaxEvents 1 -FilterXPath $filter
$Message = $A.Message
$EventID = $A.Id
$MachineName = $A.MachineName
$Source = $A.ProviderName
$EmailFrom = "sios@medfordband.com"
$EmailTo = "sios@medfordband.com"
$Subject ="Alert From $MachineName"
$Body = "EventID: $EventID`nSource: $Source`nMachineName: $MachineName `n$Message"
$SMTPServer = "smtp.gmail.com"
$SMTPClient = New-Object Net.Mail.SmtpClient($SmtpServer, 587)
$SMTPClient.EnableSsl = $true
$SMTPClient.Credentials = New-Object System.Net.NetworkCredential("sios@medfordband.com", "MySMTPP@55w0rd");
$SMTPClient.Send($EmailFrom, $EmailTo, $Subject, $Body)
An example of an email generated from that Powershell script looks like this.
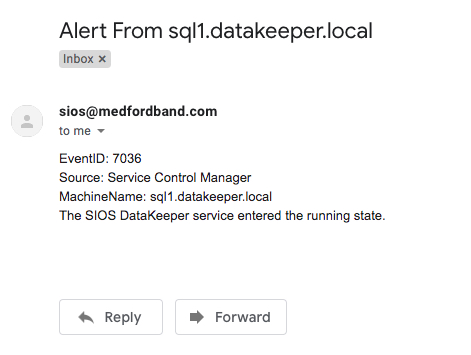
You probably noticed that this Powershell script uses the Get-WinEvent cmdlet to grab the most recent Event Log entry based upon the LogName, EventID and EventData specified. It then parses that event and assigns the EventID, Source, MachineName and Message to variables that will be used to compose the email. You will see that the LogName, EventID and EventData specified is the same as what you will specify when you set up the Scheduled Task in Step 2.
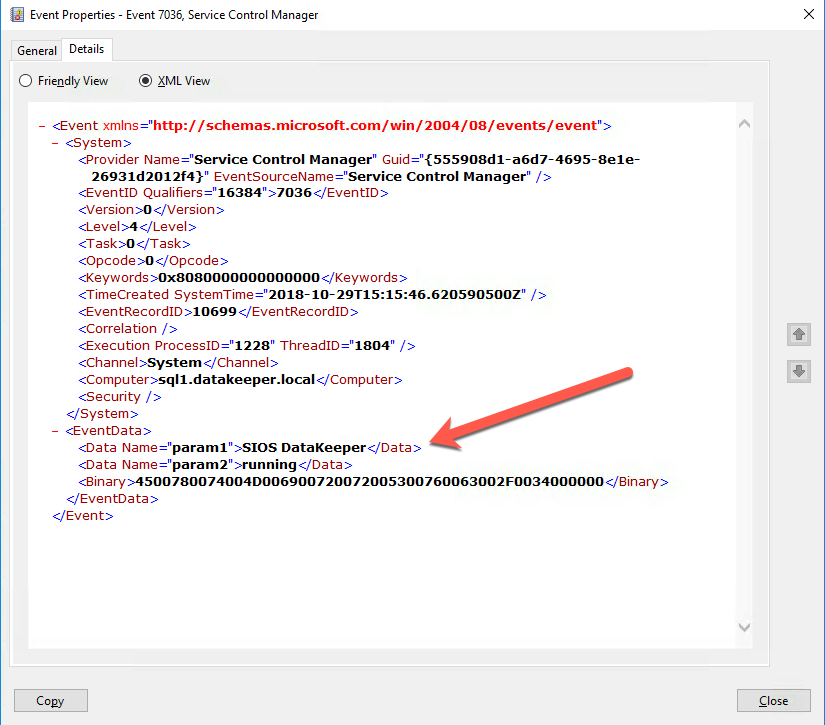
While EventID, LogName are probably familiar to you, EventData may not be as familiar. To see the EventData associated with a particular Event you will need to open the Event in Event Viewer, look at the Details tab and then select XML view. From the XML view you can see all the data included with an event. Near the bottom of the XML you will see an array of data called <EventData>. Within there you will find additional Event Data stored as parameters. As show below, in the “param1” we will find the name of the Service being that either stopped or started.
Step 2 – Set Up a Scheduled Task
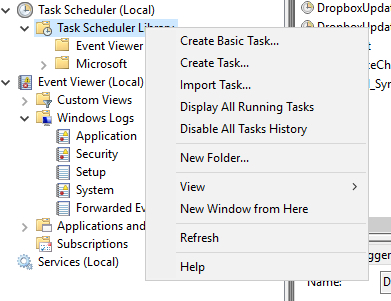
In Task Scheduler Create a Task as show in the following screen shots.
- Create Task
 Make sure the task is set to Run whether the user is logged on or not.
Make sure the task is set to Run whether the user is logged on or not.
- On the Triggers tab choose New to create a Trigger that will begin the task “On an Event”. In my example I will be creating an event that triggers any time DataKeeper (extmirr) logs an important event to the System log.

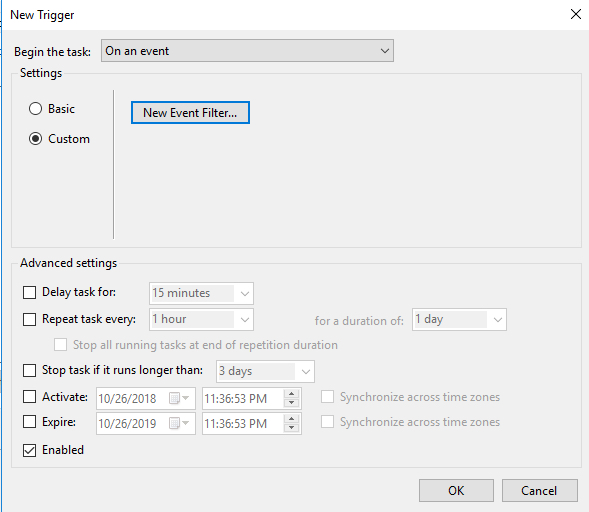
Create a custom event and New Event Filter as shown below…For my trigger you can start my setting up a trigger that monitors 7036 as I describe in my previous article. However, the Filter GUI interface does not allow us to specify the Service Name stored in Param1 of EventData as I described earlier. In order to monitor for just the specific service we are interested in we will need to edit the XML directly as shown below.
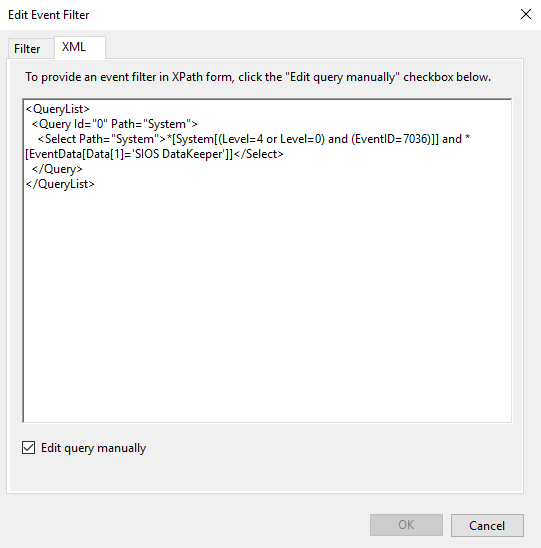
If you rather just skip straight to the chase feel free to copy my XML below and replace ‘SIOS DataKeeper’ with the event data stored in param1 of the Event you want to monitor.<QueryList> <Query Id="0" Path="System"> <Select Path="System">*[System[(Level=4 or Level=0) and (EventID=7036)]] and *[EventData[Data[1]='SIOS DataKeeper']]</Select> </Query> </QueryList>
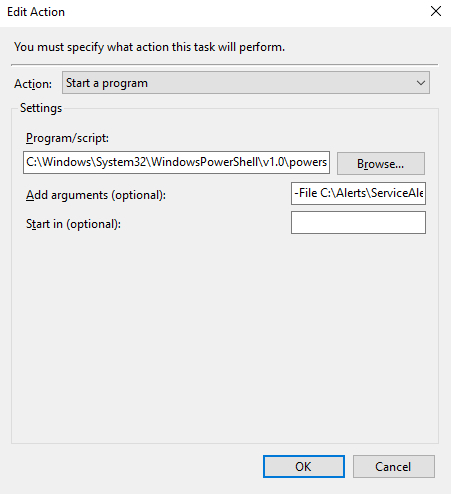
- Once the Event Trigger is configured, you will need to configure the Action that occurs when the event is run. In our case we are going to run the Powershell script that we created in Step 1.
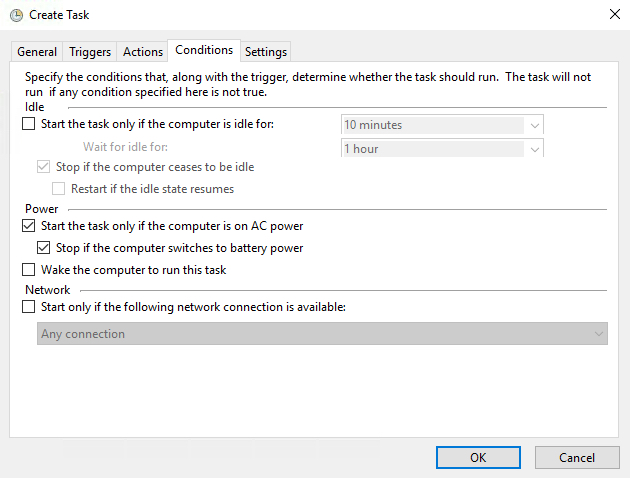
- The default Condition parameters should be sufficient.
- And finally, on the Settings tab make sure you allow the task to be run on demand and to “Queue a new instance” if a task is already running.

Step 3 (if necessary) – Fix the Microsoft-Windows-DistributedCOM Event ID: 10016 Error
In theory, if you did everything correctly you should now start receiving emails any time one of the events you are monitoring gets logged in the event log. However, I ran into a weird permission issue on one of my servers that I had to address before everything worked. I’m not sure if you will run into this issue, but just in case here is the fix.
In my case when I manually triggered the event, or if I ran the Powershell script directly, everything worked as expected and I received an email. However, if one of the EventIDs being monitored was logged into the event log it would not result in an email being sent. The only clue I had was the Event ID: 10016 that was logged in my Systems event log each time I expected the Task Trigger to detect a logged event.
Log Name: System
Source: Microsoft-Windows-DistributedCOM
Date: 10/27/2018 5:59:47 PM
Event ID: 10016
Task Category: None
Level: Error
Keywords: Classic
User: DATAKEEPER\dave
Computer: sql1.datakeeper.local
Description:
The application-specific permission settings do not grant Local Activation permission for the COM Server application with CLSID
{D63B10C5-BB46-4990-A94F-E40B9D520160}
and APPID
{9CA88EE3-ACB7-47C8-AFC4-AB702511C276}
to the user DATAKEEPER\dave SID (S-1-5-21-25339xxxxx-208xxx580-6xxx06984-500) from address LocalHost (Using LRPC) running in the application container Unavailable SID (Unavailable). This security permission can be modified using the Component Services administrative tool.
Many of the Google search results for that error indicate that the error is benign and include instructions on how to suppress the error instead of fixing it. However, I was pretty sure this error was the cause of my current failure to be able to send an email alert from a Scheduled Event that was triggered from a monitored Event Log entry, so I needed to fix it.
After much searching, I stumbled upon this newsgroup discussion. The response from Marc Whittlesey pointed me in the right direction. This is what he wrote…
There are 2 registry keys you have to set permissions before you go to the DCOM Configuration in Component services: CLSID key and APPID key.
I suggest you to follow some steps to fix issue:
1. Press Windows + R keys and type regedit and press Enter.
2. Go to HKEY_Classes_Root\CLSID\*CLSID*.
3. Right click on it then select permission.
4. Click Advance and change the owner to administrator. Also click the box that will appear below the owner line.
5. Apply full control.
6. Close the tab then go to HKEY_LocalMachine\Software\Classes\AppID\*APPID*.
7. Right click on it then select permission.
8. Click Advance and change the owner to administrators.
9. Click the box that will appear below the owner line.
10. Click Apply and grant full control to Administrators.
11. Close all tabs and go to Administrative tool.
12. Open component services.
13. Click Computer, click my computer, and then click DCOM.
14. Look for the corresponding service that appears on the error viewer.
15. Right click on it then click properties.
16. Click security tab then click Add User, Add System then apply.
17. Tick the Activate local box.So use the relevant keys here and the DCOM Config should give you access to the greyed out areas:
CLSID {D63B10C5-BB46-4990-A94F-E40B9D520160}APPID {9CA88EE3-ACB7-47C8-AFC4-AB702511C276}
I was able to follow Steps 1-15 pretty much verbatim. However, when I got to Step 16 I really couldn’t tell exactly what he wanted me to do. At first I granted the DATAKEEPER\dave user account Full Control to the RuntimeBroker, but that didn’t fix things. Eventually I just selected “Use Default” on all three permissions and that fixed the issue.

I’m not sure how or why this happened, but I figured I better write it all down in case it happens again because it took me a while to figure it out.
Step 4 – Automating the Deployment
If you need to enable the same alerts on multiple systems you can simply export your Task to an XML file and Import it on your other systems.
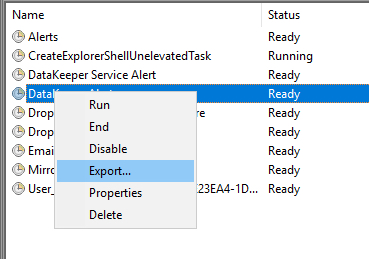
Or even better yet, automate the Import as part of your build process through a Powershell script after making your XML file available on a file share as shown in the following example.
PS C:\> Register-ScheduledTask -Xml (get-content '\\myfileshare\tasks\DataKeeperAlerts.xml' | out-string) -TaskName "DataKeeper Service Alerts" -User datakeeper\dave -Password MyDomainP@55W0rd –Force
In Summary
Hopefully what I have provided will give you everything you need to start receiving alert notification emails on whichever Windows Services keep you up at night.
This concludes my series on configuring email alerts. In this series I covered covered configuring alerts based on Perfmon counters, Event Log Entries and in this article Windows Service Start and Stop events. Of course you can extend these Powershell scripts described in these articles to do more than just send emails. Many alerts or unexpected service stoppages generally require some remediation, so why not just script out the recovery steps and let the triggered task take care of the issue for you?
Personally I recommend that you invest in SCOM , SolarWinds or some other Enterprise Management System, but if that is not in the cards where you work then these articles can help in a pinch.
Step-by-Step: How to Trigger an Email Alert from a Windows Event that Includes the Event Details using Windows Server 2016
Introduction
Setting up an email alert is as simple as creating a Windows Task that is triggered by an Event. You then must specify the action that will occur when that Task is triggered. Since Microsoft has decided to deprecate the “Send an e-mail” option the only choice we have is to Start a Program. In our case that program will be a Powershell script that will collect the Event Log information and parse it so that we can send an email that includes important Log Event details.
This work was verified on Windows Server 2016, but I suspect it should work on Windows Server 2012 R2 and Windows Server 2019 as well. If you get it working on any other platforms please comment and let us know if you had to change anything.
Step 1 – Write a Powershell Script
The first thing that you need to do is write a Powershell script that when run can send an email. While researching this I discovered many ways to accomplish this task, so what I’m about to show you is just one way, but feel free to experiment and use what is right for your environment.
In my lab I do not run my own SMTP server, so I had to write a script that could leverage my Gmail account. You will see in my Powershell script the password to the email account that authenticates to the SMTP server is in plain text. If you are concerned that someone may have access to your script and discover your password then you will want to encrypt your credentials. Gmail requires and SSL connection so your password should be safe on the wire, just like any other email client.
Here is an example of a Powershell script that when used in conjunction with Task Scheduler which will send an email alert automatically when any specified Event is logged in the Windows Event Log. In my environment I saved this script to C:\Alerts\DataKeeper.ps1
$EventId = 16,20,23,150,219,220
$A = Get-WinEvent -MaxEvents 1 -FilterHashTable @{Logname = "System" ; ID = $EventId}
$Message = $A.Message
$EventID = $A.Id
$MachineName = $A.MachineName
$Source = $A.ProviderName
$EmailFrom = "sios@medfordband.com"
$EmailTo = "sios@medfordband.com"
$Subject ="Alert From $MachineName"
$Body = "EventID: $EventID`nSource: $Source`nMachineName: $MachineName `nMessage: $Message"
$SMTPServer = "smtp.gmail.com"
$SMTPClient = New-Object Net.Mail.SmtpClient($SmtpServer, 587)
$SMTPClient.EnableSsl = $true
$SMTPClient.Credentials = New-Object System.Net.NetworkCredential("sios@medfordband.com", "mySMTPP@55w0rd");
$SMTPClient.Send($EmailFrom, $EmailTo, $Subject, $Body)
An example of an email generated from that Powershell script looks like this.
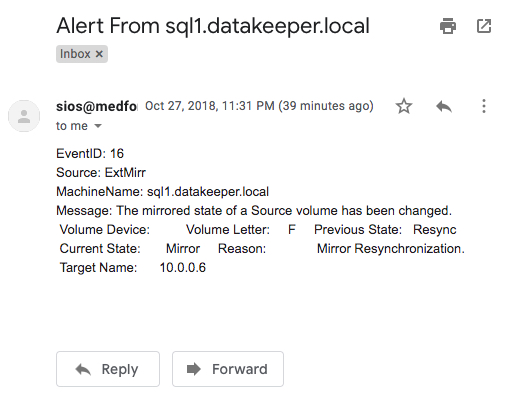
You probably noticed that this Powershell script uses the Get-WinEvent cmdlet to grab the most recent Event Log entry based upon the LogName, Source and eventIDs specified. It then parses that event and assigns the EventID, Source, MachineName and Message to variables that will be used to compose the email. You will see that the LogName, Source and eventIDs specified are the same as the ones you will specify when you set up the Scheduled Task in Step 2.
Step 2 – Set Up a Scheduled Task
In Task Scheduler Create a Task as show in the following screen shots.
- Create Task
Make sure the task is set to Run whether the user is logged on or not.
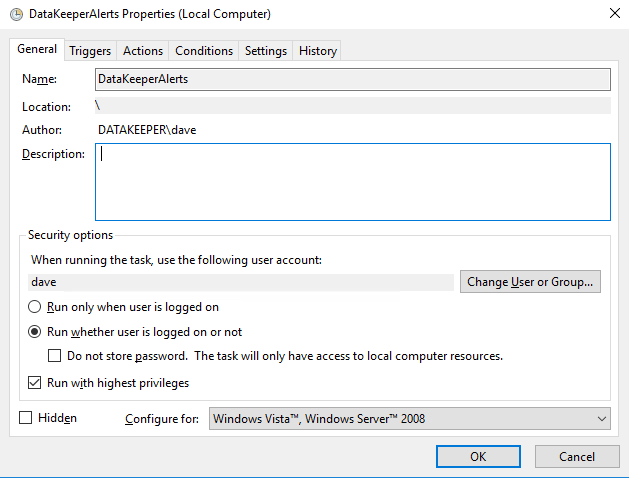
- On the Triggers tab choose New to create a Trigger that will begin the task “On an Event”. In my example I will be creating an event that triggers any time DataKeeper (extmirr) logs an important event to the System log.
Create a custom event and New Event Filter as shown below…For my trigger I am triggering on commonly monitored SIOS DataKeeper (ExtMirr) EventIDs 16, 20, 23,150,219,220 . You will need to set up your event to trigger on the specific Events that you want to monitor. You can put multiple Triggers in the same Task if you want to be notified about events that come from different logs or sources.
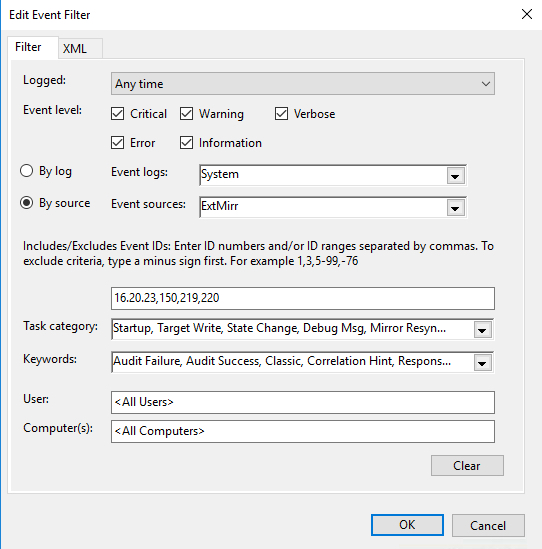
Create a New Event Filter - Once the Event Trigger is configured, you will need to configure the Action that occurs when the event is run. In our case we are going to run the Powershell script that we created in Step 1.

- The default Condition parameters should be sufficient.
- And finally, on the Settings tab make sure you allow the task to be run on demand and to “Queue a new instance” if a task is already running.
Step 3 (if necessary) – Fix the Microsoft-Windows-DistributedCOM Event ID: 10016 Error
In theory, if you did everything correctly you should now start receiving emails any time one of the events you are monitoring gets logged in the event log. However, I ran into a weird permission issue on one of my servers that I had to address before everything worked. I’m not sure if you will run into this issue, but just in case here is the fix.
In my case when I manually triggered the event, or if I ran the Powershell script directly, everything worked as expected and I received an email. However, if one of the EventIDs being monitored was logged into the event log it would not result in an email being sent. The only clue I had was the Event ID: 10016 that was logged in my Systems event log each time I expected the Task Trigger to detect a logged event.
Log Name: System
Source: Microsoft-Windows-DistributedCOM
Date: 10/27/2018 5:59:47 PM
Event ID: 10016
Task Category: None
Level: Error
Keywords: Classic
User: DATAKEEPER\dave
Computer: sql1.datakeeper.local
Description:
The application-specific permission settings do not grant Local Activation permission for the COM Server application with CLSID
{D63B10C5-BB46-4990-A94F-E40B9D520160}
and APPID
{9CA88EE3-ACB7-47C8-AFC4-AB702511C276}
to the user DATAKEEPER\dave SID (S-1-5-21-25339xxxxx-208xxx580-6xxx06984-500) from address LocalHost (Using LRPC) running in the application container Unavailable SID (Unavailable). This security permission can be modified using the Component Services administrative tool.
Many of the Google search results for that error indicate that the error is benign and include instructions on how to suppress the error instead of fixing it. However, I was pretty sure this error was the cause of my current failure to be able to send an email alert from a Scheduled Event that was triggered from a monitored Event Log entry, so I needed to fix it.
After much searching, I stumbled upon this newsgroup discussion. The response from Marc Whittlesey pointed me in the right direction. This is what he wrote…
There are 2 registry keys you have to set permissions before you go to the DCOM Configuration in Component services: CLSID key and APPID key.
I suggest you to follow some steps to fix issue:
1. Press Windows + R keys and type regedit and press Enter.
2. Go to HKEY_Classes_Root\CLSID\*CLSID*.
3. Right click on it then select permission.
4. Click Advance and change the owner to administrator. Also click the box that will appear below the owner line.
5. Apply full control.
6. Close the tab then go to HKEY_LocalMachine\Software\Classes\AppID\*APPID*.
7. Right click on it then select permission.
8. Click Advance and change the owner to administrators.
9. Click the box that will appear below the owner line.
10. Click Apply and grant full control to Administrators.
11. Close all tabs and go to Administrative tool.
12. Open component services.
13. Click Computer, click my computer, and then click DCOM.
14. Look for the corresponding service that appears on the error viewer.
15. Right click on it then click properties.
16. Click security tab then click Add User, Add System then apply.
17. Tick the Activate local box.So use the relevant keys here and the DCOM Config should give you access to the greyed out areas:
CLSID {D63B10C5-BB46-4990-A94F-E40B9D520160}APPID {9CA88EE3-ACB7-47C8-AFC4-AB702511C276}
I was able to follow Steps 1-15 pretty much verbatim. However, when I got to Step 16 I really couldn’t tell exactly what he wanted me to do. At first I granted the DATAKEEPER\dave user account Full Control to the RuntimeBroker, but that didn’t fix things. Eventually I just selected “Use Default” on all three permissions and that fixed the issue.
I’m not sure how or why this happened, but I figured I better write it all down in case it happens again because it took me a while to figure it out.
Step 4 – Automating the Deployment
If you need to enable the same alerts on multiple systems you can simply export your Task to an XML file and Import it on your other systems.
Or even better yet, automate the Import as part of your build process through a Powershell script after making your XML file available on a file share as shown in the following example.
PS C:\> Register-ScheduledTask -Xml (get-content '\\myfileshare\tasks\DataKeeperAlerts.xml' | out-string) -TaskName "DataKeeperAlerts" -User datakeeper\dave -Password MyDomainP@55W0rd –Force
In Summary
Hopefully what I have provided will give you everything you need to start receiving alert notification emails on whichever Event Log entries keep you up at night.
In my next post I will show you how to be notified when a specified Service either starts or stops. Of course you could just monitor for EventID 7036 from Service Control Monitor, but that would notify you whenever ANY service starts or stops. We will need to dig a little deeper to make sure we get notified only when the services we care about start or stop.
Azure Outage Post-Mortem Part 3
My previous blog posts, Azure Outage Post-Mortem – Part 1 and Azure Outage Post-Mortem Part 2,made some assumptions based upon limited information coming from blog posts and twitter. I just attended a session at Ignite which gave a little more clarity as to what actually happened. Sometime tomorrow you should be able to view the session for yourself.
BRK3075 – Preparing for the unexpected: Anatomy of an Azure outage
The official Root Cause Analysis they said will be published soon, but in the meantime here are some tidbits of information gleaned from the session.
The outage was NOT caused by a lightning strike as previously reported. Instead, due to the nature of the storm there were electrical storm sags and swells, which locked out a chiller plant in the 1st datacenter. During this first outage they were able to recover the chiller quickly with no noticeable impact. Shortly thereafter, there was a second outage at a second datacenter which was not recovered properly, which began an unfortunate series of events.
During this 2nd outage, Microsoft states that “Engineers didn’t triage alerts correctly – chiller plant recovery was not prioritized”. There were numerous alerts being triggered at this time, and unfortunately the chiller being offline did not receive the priority it should have. The RCA as to why that happened is still being investigated.
Microsoft states that of course redundant chiller systems are in place. However, the cooling systems were not set to automatically failover. Recently installed new equipment had not been fully tested, so it was set to manual mode until testing had been completed.
After 45 minutes the ambient cooling failed, hardware shutdown, air handlers shut down because they thought there was a fire, and staff had been evacuated due to the false fire alarm. During this time temperature in the data center was increasing and some hardware was not shut down properly, causing damage to some storage and networking.
After manually resetting the chillers and opening the air handlers the temperature began to return to normal. It took about 3 hours and 29 minutes before they had a complete picture of the status of the datacenter.
The biggest issue was there was damage to storage. Microsoft’s primary concern is data protection, so short of the enter datacenter sinking into a sinkhole or a meteor strike taking out the datacenter, Microsoft will work to recover data to ensure no data loss. This of course took some time, which extend the overall length of the outage. The good news is that no customer data was lost, the bad news is that it seemed like it took 24-48 hours for things to return to normal, based upon what I read on Twitter from customers complaining about the prolonged outage.
Everyone expected that this outage would impact customers hosted in the South Central Region, but what they did not expect was that the outage would have an impact outside of that region. In the session, Microsoft discusses some of the extended reach of the outage.
Azure Service Manager (ASM) – This controls Azure “Classic” resources, AKA, pre-ARM resources. Anyone relying on ASM could have been impacted. It wasn’t clear to me why this happened, but it appears that South Central Region hosts some important components of that service which became unavailable.
Visual Studio Team Service (VSTS) – Again, it appears that many resources that support this service are hosted in the South Central Region. This outage is described in great detail by Buck Hodges (@tfsbuck), Director of Engineering, Azure DevOps this blog post.
Postmortem: VSTS 4 September 2018
Azure Active Directory (AAD) – When the South Central region failed, AAD did what it was designed to due and started directing authentication requests to other regions. As the East Coast started to wake up and online, authentication traffic started picking up. Now normally AAD would handle this increase in traffic through autoscaling, but the autoscaling has a dependency on ASM, which of course was offline. Without the ability to autoscale, AAD was not able to handle the increase in authentication requests. Exasperating the situation was a bug in Office clients which made them have very aggressive retry logic, and no backoff logic. This additional authentication traffic eventually brought AAD to its knees.
They ran out of time to discuss this further during the Ignite session, but one feature that they will be introducing will be giving users the ability to failover Storage Accounts manually in the future. So in the case where recovery time objective (RTO) is more important than (RPO) the user will have the ability to recover their asynchronously replicated geo-redundant storage in an alternate data center should Microsoft experience another extended outage in the future.
Until that time, you will have to rely on other replication solutions such as SIOS DataKeeper Azure Site Recovery, or application specific replication solutions which give you the ability to replicate data across regions and put the ability to enact your disaster recovery plan in your control.
Azure Outage Post-Mortem Part 2
My previous blog post says that Cloud-to-Cloud or Hybrid-Cloud would give you the most isolation from just about any issue a CSP could encounter. However, in this particular failure had Availability Zones been available in the South Central region most of the downtime caused by this natural disaster could have been avoided. Microsoft published a Preliminary RCA of the September 4th South Central Outage.
The most important part of that whole summary is as follows…
“Despite onsite redundancies, there are scenarios in which a datacenter cooling failure can impact customer workloads in the affected datacenter.”
What does that mean to you? If your applications all run in the same datacenter you are susceptible to the same type of outage in the future. In Microsoft’s defense, this really shouldn’t be news to you as this has always been true whether you run in Azure, AWS, Google or even your own datacenter. Failure to plan ahead with data replication to a different datacenter and a plan in place to quickly recover your applications in those datacenters in the event of a disaster is simply a lack of planning on your part.
While Microsoft doesn’t publish exact Availability Zone locations, if you believe this map published here you could guess that they are probably anywhere from a 2-10 miles apart from each other.
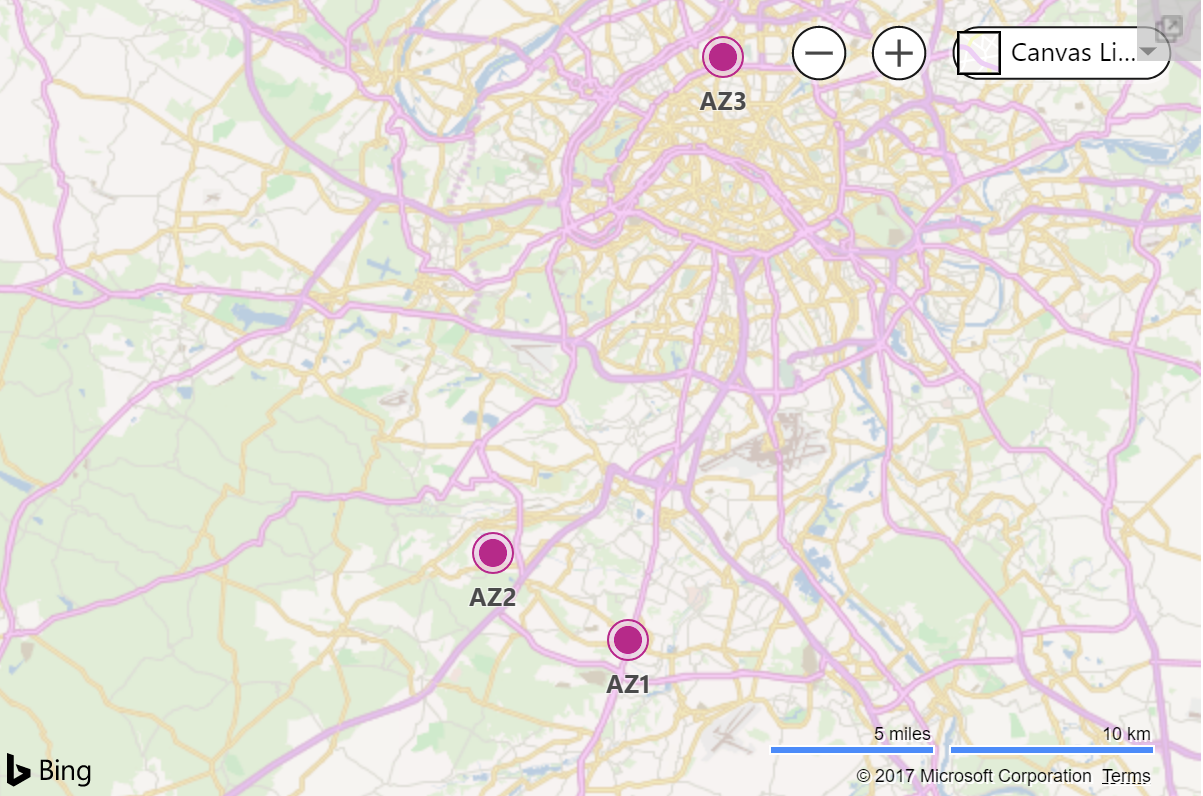
In all but the most extreme cases, replicating data across Availability Zones should be sufficient for data protection. Some applications such as SQL Server have built in replication technology, but for a broad range of applications, operating systems and data types you will want to investigate block level replication SANless cluster solutions. SANless cluster solutions have traditionally been used for multisite clusters, but the same technology can also be used in the cloud across Availability Zones, Regions, or Hybrid-Cloud for high availability and disaster recovery.
Implementing a SANless cluster that spans Availability Zones, whether it is Azure, AWS or Google, is a pretty simple process given the right tools. Here are a few resources to help get you started.
Step-by-Step: Configuring a File Server Cluster in Azure that Spans Availability Zones
How to Build a SANless SQL Server Failover Cluster Instance in Google Cloud Platform
MS SQL Server v.Next on Linux with Replication and High Availability #Azure #Cloud #Linux
Deploying Microsoft SQL Server 2014 Failover Clusters in #Azure Resource Manager (ARM)
SANless SQL Server Clusters in AWS
SANless Linux Cluster in AWS Quick Start
If you are in Azure you may also want to consider Azure Site Recovery (ASR). ASR lets you replicate the entire VM from one Azure region to another region. ASR will replicate your VMs in real-time and allow you to do a non-disruptive DR test whenever you like. It supports most versions of Windows and Linux and is relatively easy to set up.
You can also create replication jobs that have “Multi-VM Consistency”, meaning that servers that must be recovered from the exact same point in time can be put together in this consistency group and they will have the exact same recovery point. What this means is if you wanted to build a SANless cluster with DataKeeper in a single region for high availability you have two options for DR. One is you could extend your SANless cluster to a node in a different region, or else you could simply use ASR to replicate both nodes in a consistency group.

The trade off with ASR is that the RPO and RTO is not as good as you will get with a SANless multi-site cluster, but it is easy to configure and works with just about any application. Just be careful, if your application exceeds 10 MBps in disk write activity on a regular basis ASR will not be able to keep up. Also, clusters based on Storage Spaces Direct cannot be replicated with ASR and in general lack a good DR strategy when used in Azure.
For a while after Managed Disks were released ASR did not fully support them until about a year later. Full support for Managed Disks was a big hurdle for many people looking to use ASR. Fortunately since about February of 2018 ASR fully supports Managed Disks. However, there is another problem that was just introduced.
With the introduction of Availability Zones ASR is once again caught behind the times as they currently don’t support VMs that have been deployed in Availability Zones.

I went ahead and tried it anyway. I seemed to be able to configure replication and was able to do a test failover.
I’m hoping to find out more about this limitation at the Ignite conference. I don’t think this limitation is as critical as the Managed Disk limitation was, just because Availability Zones aren’t widely available yet. So hopefully ASR will pick up support for Availability Zones as other regions light up Availability Zones and they are more widely adopted.
Lightning Never Strikes Twice: Surviving the #Azure Cloud Outage
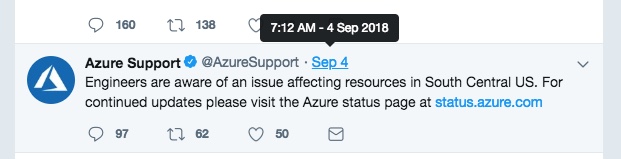
Yesterday morning I opened my Twitter feed to find that many people were impacted by an Azure outage. When I tried to access the resource page that described the outage and the current resources impacted even that page was unavailable. @AzureSupport was providing updates via Twitter.
The original update from @AzureSupport came in at 7:12 AM EDT
Looking back on the Twitter feed it seems as if the problem initially began an hour or two before that.
It quickly became apparent that the outages had a wider spread impact than just the SOUTH CENTRAL US region as originally reported. It seems as if services that relied on Azure Active Directory could have been impacted as well and customers trying to provision new subscriptions were having issues.

And 24 hours later the problem has not been completely resolved and it according to the last update this morning…


So what could you have done to minimize the impact of this outage? No one can blame Microsoft for a natural disaster such as a lightning strike. But at the end of the day if your only disaster recovery plan is to call, tweet and email Microsoft until the issue is resolved, you just received a rude awakening. IT IS UP TO YOU to ensure you have covered all the bases when it comes to your disaster recovery plan.
While the dust is still settling on exactly what was impacted and what customers could have done to minimize the downtime, here are some of my initial thoughts.
Availability Sets (Fault Domains/Update Domains) – In this scenario, even if you built Failover Clusters, or leveraged Azure Load Balancers and Availability Sets, it seems the entire region went offline so you still would have been out of luck. While it is still recommended to leverage Availability Sets, especially for planned downtime, in this case you still would have been offline.
Availability Zones – While not available in the SOUTH CENTRAL US region yet, it seems that the concept of Availability Zones being rolled out in Azure could have minimized the impact of the outage. Assuming the lightning strike only impacted one datacenter, the other datacenter in the other Availability Zone should have remained operational. However, the outages of the other non-regional services such as Azure Active Directory (AAD) seems to have impacted multiple regions, so I don’t think Availability Zones would have isolated you completely.
Global Load Balancers, Cross Region Failover Clusters, etc. – Whether you are building SANLess clusters that cross regions, or using global load balancers to spread the load across multiple regions, you may have minimized the impact of the outage in SOUTH CENTRAL US, but you may have still been susceptible to the AAD outage.
Hybrid-Cloud, Cross Cloud – About the only way you could guarantee resiliency in a cloud wide failure scenario such as the one Azure just experienced is to have a DR plan that includes having realtime replication of data to a target outside of your primary cloud provider and a plan in place to bring applications online quickly in this other location. These two locations should be entirely independent and should not rely on services from your primary location to be available, such as AAD. The DR location could be another cloud provider, in this case AWS or Google Cloud Platform seem like logical alternatives, or it could be your own datacenter, but that kind of defeats the purpose of running in the cloud in the first place.
Software as a Service – While Software as service such as Azure Active Directory (ADD), Azure SQL Database (Database-as-Service) or one of the many SaaS offerings from any of the cloud providers can seem enticing, you really need to plan for the worst case scenario. Because you are trusting a business critical application to a single vendor you may have very little control in terms of DR options that includes recovery OUTSIDE of the current cloud service provider. I don’t have any words of wisdom here other than investigate your DR options before implementing any SaaS service, and if recovery outside of the cloud is not an option than think long and hard before you sign-up for that service. Minimally make the business stake owners aware that if the cloud service provider has a really bad day and that service is offline there may be nothing you can do about it other than call and complain.
I think in the very near future you will start to hear more and more about cross cloud availability and people leveraging solutions like SIOS DataKeeper to build robust HA and DR strategies that cross cloud providers. Truly cross cloud or hybrid cloud models are the only way to truly insulate yourself from most conceivable cloud outages.
If you were impacted from this latest outage I’d love to hear from you. Tell me what went down, how long you were down, and what you did to recover. What are you planning to do so that in the future your experience is better?
“Incomplete Communication with Cluster” with local Storage Space for SQL Server cluster
When building a SANless SQL Server cluster with SIOS DataKeeper, or when configuring Always On Availability Groups for SQL Server, you may consider striping together multiple disk in a Simple Storage Space (RAID 0) for performance. This is very commonly done in the cloud where each instance typically his backed by hardware resiliency, so RAID 0 is not really all that risky.
For instance, I had a recent customer in AWS that wanted to max out his IOPS to 80,000, the maximum IOPS currently available to a single instance. Now keep in mind, only the largest EBS optimized instance sizes supports 80,000 IOPS, so you want to make sure you know what maximum IOPS your particular instance size supports.
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/EBSOptimized.html
In this case we had ac5.18xlarge instance which does support 80,000 IOPS. However, any individual EBS Provisioned IOPS volume only supports up to 32,000 IOPS. The only way to achieve 80,000 IOPS when writing to any single volume is to strip three of these volumes together in a Simple Storage Space.
Herein lies the rub, if you try to do that in an existing cluster things are going to go haywire pretty fast. Fellow MVP Joey D’Antoni recently blogged about the issue and it appears to still be an issue in the Windows Server 2019 preview.
Just as Joey suggests, I always advise my customers to build out the nodes and any Storage Spaces BEFORE they start the clustering process. This makes the process go much smoother. It also allows the customer to have some time to benchmark the server’s performance before they add any replication, to ensure everything is working as expected.
Your student could be the next Doogie Howser of Cloud Computing with free training and cloud computing resources
Students with any interest in Information Technology or Computer Science are going to be joining a world dominated by Cloud Computing. And of course the major cloud service providers (CSP) would all love to see the young people embrace their cloud platform to host the next big thing like Facebook, Instagram or SnapChat. The top three CSP all have free offerings for students, hoping to win their minds and hearts.
But before you jump right in to cloud computing, the novice student might want to start with some basic fundamentals of computer programming at one of the many free online resources, including Khan Academy.

Microsoft is offering free Azure services for students. There are two different offerings. The first is targeted at high school students ages 13+ and the second is geared towards college students 18+.

Microsoft Azure for Students Starter Offer is for those high school students that are interested in building applications in the cloud. While there are not as many free services or credits as being offered at the college level, there is certainly enough available for free to really get some hands on experience with some cutting edge technology for the self starter. How cool would it be for your high school to start a Cloud Computing Club, or to integrate this offering into some of the IT classes they may already be taking.
Azure for Students is targeted at the college level student and has many more features available for free. Any student in computer science or information technology should definitely get some hands on experience with these cutting edge cloud technologies and this is the perfect way to do it with no additional out of pocket expense.
A good way to get introduced to the Azure Cloud is to start with some free online training courses Microsoft delivers in partnership with Pluralsight.
![]()
AWS Educate. Not to be outdone, AWS also offers some free cloud services to students and educators. These seem to be in terms of free cloud credits, which if managed properly can go a long way. AWS also delivers an educational program that can be combined with an AP class in Computer Science if your high school wants to participate.

Google Cloud Platform (GCP) also has education grants available for computer science majors at accredited universities. These seem to be the most restrictive of the three as they are available for Computer Science Majors only at accredited universities.
GCP does also offer training, but from what I can find I don’t see any free training offerings. If you want some hands on training you will have to register for some classes. The plus side of this is that these classes all seem to be instructor led, either online or in an actual classroom. The downside is I don’t think a lot of 13 year olds are going to shell out any money to start developing on the CGP when there are other free training opportunities available on AWS or Azure.
For the ambitious young student, the resources are certainly there for you to be the next Doogie Howser of Cloud Computing.

