Yesterday evening Pacific Standard Time, Azure storage services experienced a service interruption across the United States, Europe and parts of Asia, which impacted multiple cloud services in these regions.
As part of a performance update to Azure Storage, an issue was discovered that resulted in reduced capacity across services utilizing Azure Storage, including Virtual Machines, Visual Studio Online, Websites, Search and other Microsoft services.
Read the whole report on the Azure blog. http://azure.microsoft.com/blog/2014/11/19/update-on-azure-storage-service-interruption/
So what does this outage mean to those thinking about a cloud deployment? Global “interruptions” of this magnitude certainly cannot occur on any regular basis for any cloud provider that intends to remain in the cloud business, whether they are Microsoft, Amazon, Google or other. However, as a cloud architect or person responsible for a cloud deployment, you have a responsibility to your customer to have a “Plan B” in your back pocket in case the worst case scenario actually happens.
What exactly is a “Plan B”? Plan B involves having a documented procedure for recovering data and services in an alternate location in the event of a wide spread outage that impacts a cloud provider’s ability to deliver their service, despite deploying what you thought was a highly resilient cloud deployment designed to keep running even in the event of localized outages within a region, availability zone or fault domain.
At a high level you should be concerned about three things: Data Recovery, Application Recovery, and Client Access. There are many ways to address these concerns, some more automated than others and some with a better Recovery Time Objective (RTO) and Recovery Point Objective (RPO) than others.
It was just last week that I blogged about how to create a multisite cluster that stretched between the AWS cloud and the Azure cloud. This type of configuration is just what is needed in the event of an outage of the magnitude that we just experienced yesterday in the Azure cloud. https://clusteringformeremortals.com/2014/11/18/cloud-resiliency-for-sqlserver-failover-clusters-aws-to-azure-multisite-cluster/
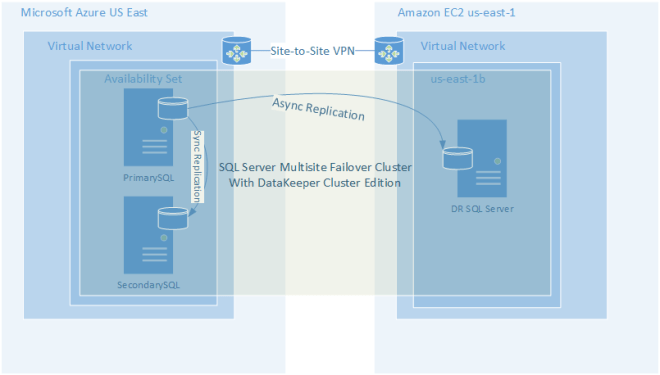
Figure 1 – Example of a Cloud-to-Cloud Multisite Cluster Configuration
Another alternative to the “cloud-to-cloud” replication model is of course utilizing your own datacenter as a disaster recovery site for your cloud deployment. The advantages of this is that you have physical ownership of your data, but of course now you are back in the business of managing a datacenter, which can negate some of the benefit of a pure cloud deployment.
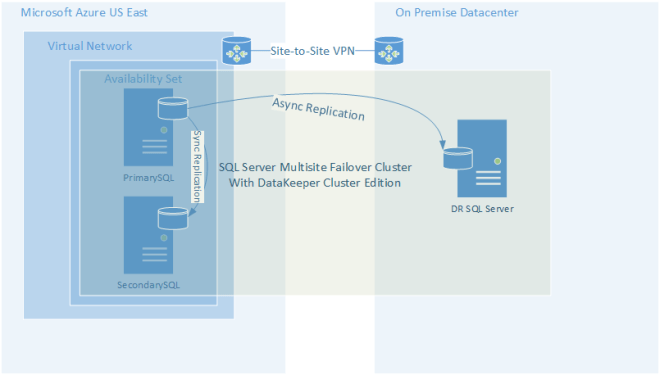
Figure 2 – Hybrid Cloud Deployment Model
If you are not ready to go full on cloud, you can still make use of the cloud as a disaster recovery site. This is probably the easiest and most cost effective way to implement an offsite datacenter for disaster recovery and to start taking advantage of what the cloud has to offer without fully committing to moving all your workloads into the cloud.
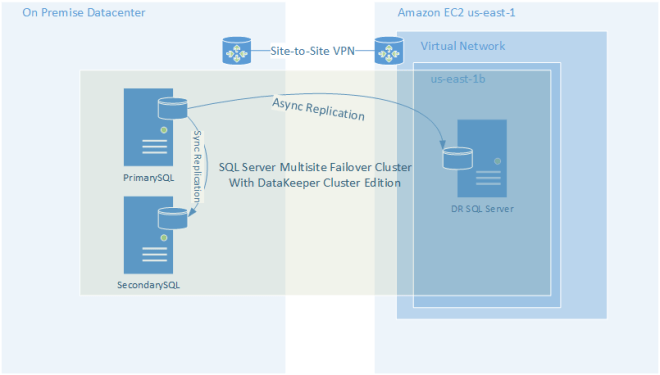
Figure 3 – Using the Cloud as a Disaster Recovery Site
The illustrations shown above make use of the host based replication solution called DataKeeper Cluster Edition to build multisite SQL Server clusters. However, DataKeeper can be used to keep any data in sync, either between different cloud providers or in the hybrid cloud model.
Microsoft is not alone in dealing with cloud outages as outages have impacted Google, Microsoft, Amazon, DropBox and many others just this year alone. Having a “Plan B” in place is a must have anytime you are relying on any cloud service.