When building HA clusters, your application availability is only as good as its weakest link. What this means is that if you bought great servers with redundant everything (CPU, fans, power, RAID, RAM, etc) and a super deluxe SAN with multi-path connectivity, multiple SAN switches and clustered your application with your favorite clustering software you probably have a very reliable application – right? Well, not necessarily. Are the servers plugged into the same UPS? Are they on the same network switch? Are they cooled by the same AC unit? Are they in the same building? Is your SAN truly reliable? Any one of these issues among others is a single point of failure in your cluster configuration and needs to be considered.
Of course, you have to know when “good enough” is “good enough”. Your budget and your SLAs will help decide what exactly is good enough. However, one area where I am concerned that people may be skimping is in the area of storage. With the advent of cheap or free iSCSI target software solutions, I am seeing some people recommend that you just throw some iSCSI target software on a spare server and voilà – instant shared storage.
Mind you I’m not talking about OEM iSCSI solutions that have built in failover technology and/or other availability features; or even storage virtualization solutions such as FalconStor. I’m talking about the guy who has a server running Windows Server 2008 that he has loaded up with storage and wants to turn it into an iSCSI target. While this is great in a lab, if you are serious about HA, you should think again. Even Microsoft only provides their iSCSI target software to qualified OEM builders experienced in delivering enterprise class storage arrays.
First of all, this is Windows, not some hardened OS built to only serve storage. It will require maintenance, security updates, hardware fixes, etc. It basically has the same reliability as the application server you are trying to protect – does it make sense to cluster your application servers but yet use the same class of server and OS to host your storage? You basically have moved your single point of failure away from your application server and moved it to your storage server – not a smart move as far as I am concerned.
Some of the Enterprise Class iSCSI target software includes synchronous and/or asynchronous replication software and snapshot capabilities. While this functionality certainly helps in terms of your recovery point objective (RPO), it won’t help your recovery time objective (RTO) unless the failover is automatic and seamless to your clustering software. If the primary iSCSI storage array fails in the middle of the night, who is going to be there to activate the replicated copy? You may be down for quite some time before you even realize there is a problem. Again, this may be “good enough”; you just need to be aware of what you are signing up for.
One thing you can do to improve the reliability of your iSCSI target server is to use a replication product such as SteelEye DataKeeper Cluster Edition to eliminate the single point of failure. Let me illustrate.
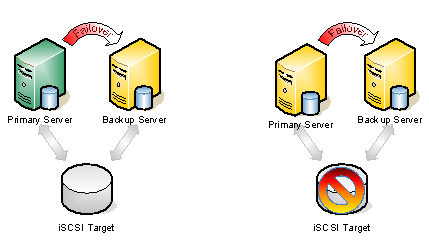
Figure 1 – Typical Shared Storage Configuration. In the event that the iSCSI target becomes unavailable, all the nodes go offline.
If we take the same configuration shown above and add a hot standby iSCSI target using SteelEye DataKeeper Cluster Edition to do replication AND automatic failover, you have just given you iSCSI target solution a whole new level of availability. That solution would look very much like this.
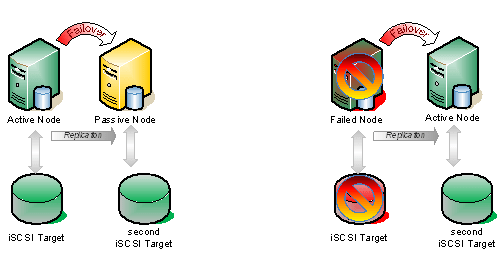
Figure 2 – In this scenario, DataKeeper Cluster Edition is replicating the iSCSI attached volume on the active node to the iSCSI attached volume on the passive node, which is connected to an entirely different iSCSI target server.
The key difference in the solution which utilizes SteelEye DataKeeper Cluster Edition vs. replication solutions provide by some iSCSI target vendors is in the integration with WSFC. The question to ask of your iSCSI solution vendor is this…
What happens if I pull the power cord on the active iSCSI target server?
If the recovery process is a manual procedure, it is not a true HA solution. If it is automatic and completely integrated with WSFC, then you have a much higher level of availability and have eliminated the iSCSI array as a single point of failure.
