They don’t go into great detail about what to do if your connection does not support multisubnetfailover=true. If your connection does NOT support that parameter, then set registerallprovidersip to false and cleanup DNS. That procedure is described best here.
I figure I get this question often enough I probably should just flesh out my response a bit, hence the reason for this post.
In general people just aren’t aware of how multi-subnet failover clusters work. Multi-subnet failover clustering support was added in Windows Server 2012 with the addition of the “OR” technology when defining cluster resource dependencies. This allowed people to allow a Cluster Name resource to be dependent upon IP Address x.x.x.x OR IP Address y.y.y.y.
x.x.x.x would be an a cluster IP resource valid in Subnet A and y.y.y.y would be a cluster IP address valid in Subnet B. Only one address will be online at any given time, whichever address was valid for the subnet the resource was currently running on.
Microsoft SQL Server started supporting this concept starting with SQL Server 2012 with both failover cluster instances (FCI) using 3-party SANless clustering solutions like SIOS DataKeeper and SQL Server Always On Availability Groups.
By default if you create a SQL Server multi-subnet failover cluster the cluster should be automatically configured optimally, including setting up the two IP addresses, adding two A records to DNS and setting the registerallprovidersIP to true. However, on the client end you need to tell it that you are connecting to a multi-subnet failover cluster, otherwise the connection won’t be made.
Configuring the client
Configuring the client is done by adding multisubnetfailover=true to the connection string. This Microsoft documentation is a great resource, but if you just search for multisubnetfailover=true you will find a lot of information about that setting.
However, not every application will support adding that to the connection string. If you find yourself in that situation you should ask your application vendor to add support for that or show you how to do it.
However, all is not lost if you find yourself in that situation. You will want to change the behavior of the cluster so that upon failover DNS is update so that the single A record associated with the cluster client access point is updated with the new IP address. This is in lieu of having two A records in DNS, one with each cluster IP address, which is the default behavior in an multi-subnet cluster.
This article reference SharePoint, you can ignore that, the rest of the article is pretty well written to describe the process you should follow.
After restarting the cluster-name-object (basically restarting the role) & cleaning up all “A” records manually (clean-up isn’t done automatically) we can see our old A-records are still in DNS so we’ll need to delete those manually.
In addition to those steps I’d advise you to reduce the TTL on the HostRecordTTL as described in this article.
With a Value of 300 you could potentially be waiting up to 5 minutes for your clients to reconnect after a failover, or even longer if if have a large Active Directory infrastructure and AD replication takes some time to update all the DNS servers across your infrastructure.
You are going to want to figure out what the optimal TTL is to facilitate quick client reconnections without over burdening your DNS servers with a bunch of DNS Lookup requests.
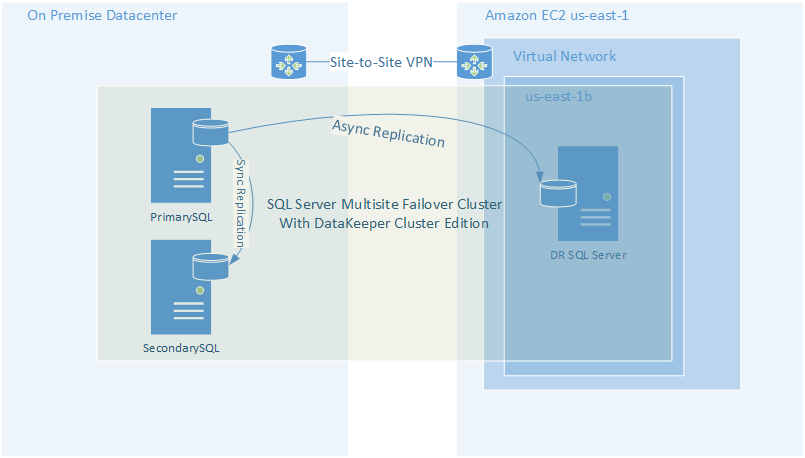
This type of configuration is common in disaster recovery configurations where your DR site is in a different subnet. It is also very common in HA deployments in AWS because different Availability Zones are in different subnets.
Let me know if you have any questions. You can always reach me on Twitter @daveberm
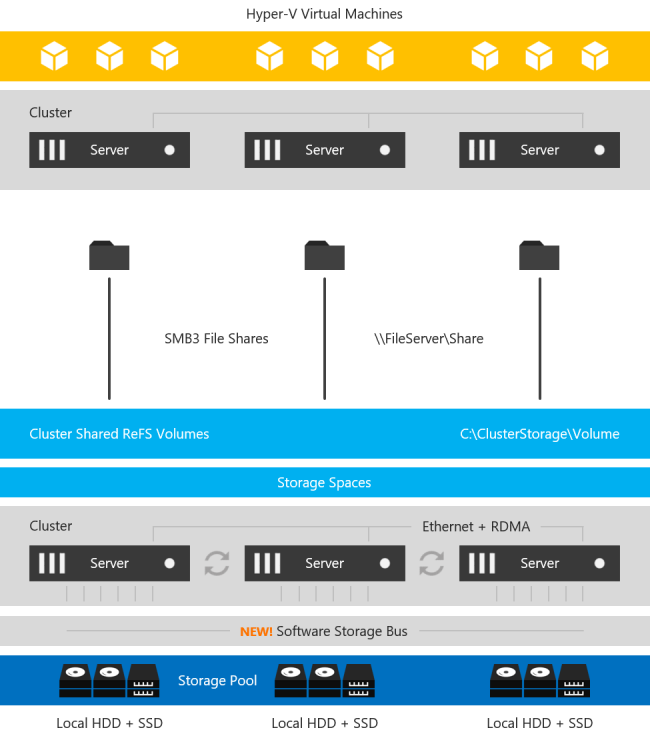
With the introduction of Windows Server 2016 DatacenterEdition a new feature called Storage Spaces Direct (S2D) was introduced. At a very high level, this solution allows you to pool together locally attached storage and present it to the cluster as a CSV for use in a Scale Out File Server, which can then be accessed over SMB 3 and used to hold cluster data such as Hyper-V VMDK files. This can also be configured in a hyper-converged (HCI) fashion such that the application and data can all run on the same set of servers. This is a grossly over-simplified description, but for details, you will want to look here.
The main use case targeted is hyper-converged infrastructure for Hyper-V deployments. However, there are other use cases, including leveraging this SMB storage to store SQL Server Data to be used in a SQL Server Failover Cluster Instance
Why would anyone want to do that? Well, for starters you can now build a highly available 2-node SQL Server Failover Cluster Instance (FCI) with SQL Server Standard Edition, without the need for shared storage. Previously, if you wanted HA without a SAN you pretty much were driven to buy SQL Server Enterprise Edition and make use of Always On Availability Groups or purchase SIOS DataKeeper and leverage the 3rd party solution which lets you build SANless clusters with any version of Windows or SQL Server. SQL Server Enterprise Edition can really drive up the cost of your project, especially if you were only buying it for the Availability Groups feature.
In addition to the cost associated with Availability Groups, there are a number of other technical reasons why you might prefer a Failover Cluster over an AG. Application compatibility, instance vs. database level protection, large number of databases, DTC support, trained staff, etc., are just some of the technical reasons why you may want to stick with a Failover Cluster Instance.
Microsoft lists both the SIOS DataKeeper solution and the S2D solution as two of the supported solutions for SQL Server FCI in their documentation here.
When comparing the two solutions, you have to take into account that SIOS has been allowing you to build SANless Clusters since 1999, while the S2D solution is still in its infancy. Having said that, there are bound to be some areas where S2D has some catching up to do, or simply features that they will never support simply due to the limitations with the technology.
Have a look at the following table for an overview of some of the things you should consider before you choose your SANless cluster solution.
If we go through this chart, we see that SIOS DataKeeper clearly has some significant advantages. For one, DataKeeper supports a much wider range of platforms, going all the way back to Windows Server 2008 R2 and SQL Server 2008 R2. The S2D solution only supports the latest releases of Windows and SQL Server 2016/2017. S2D also requires the Datacenter Edition of Windows, which can add significantly to the cost of your deployment. In addition, SIOS delivers the ONLY HA/DR solution for SQL Server on Linux that works both on-prem and in the cloud.
I’ve been talking to a lot of customers recently who are reporting some performance issues with S2D. When I tested S2D vs. DataKeeper about a year ago I didn’t see any significant differences in performance, but I did see S2D used about 2x the amount of CPU resources under the same load. This probably has to do with the high hardware requirements associated with S2D such as RDMA enabled networking and available Flash Storage, typically only available in the most expensive cloud based images.
“We recommend the I3 instance size because it satisfies the S2D hardware requirements and includes the largest and fastest instance store devices available.”
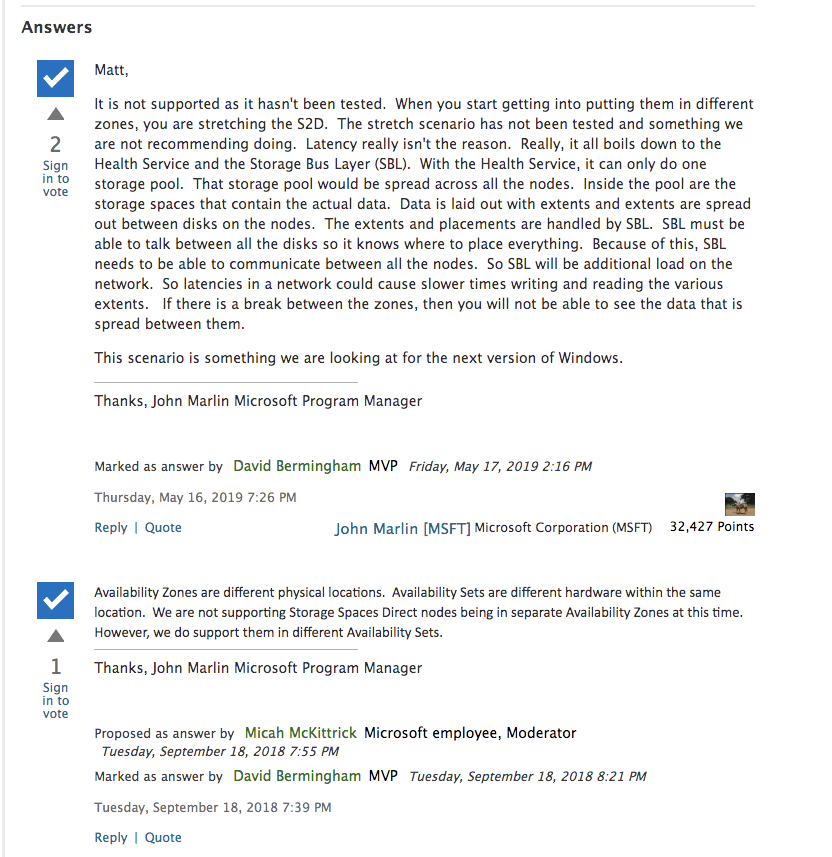
But beyond the cost and platform limitations, I think the most glaring gap comes when we start to consider that S2D does not support Availability Zones or disaster recovery configurations such as multi-site clusters or Azure Site Recovery (ASR). Allan Hirt, SQL Server Cluster guru and fellow Microsoft Cloud and Datacenter Management MVP, recently posted about this S2D limitation. In his article Revisiting Storage Spaces Direct and SQL Server FCIs Allan points out that due to the lack of support for stretching S2D clusters across sites or including an S2D based cluster as a leg in an Always On Availability Group, the best option for DR in the S2D scenario is log shipping! This even includes replicating across Availability Zones in either Azure or AWS.
Microsoft does not make it clear in their documentation, but Microsoft’s own PM for High Availability and Storage makes it perfectly clear in the Microsoft forums.
AWS also documents S2D’s lack of Availability Zone support…
“Each cluster node must be deployed in a different subnet. This architecture will be deployed into a single availability zone because Microsoft does not currently support stretch cluster with Storage Spaces Direct. ” – AWS Documentation on S2D
Deploying S2D cluster nodes within the same Availability Zone defeats the purpose of failover clustering and the deployment does not qualify for the AWS 99.99% SLA. Even if you wanted to deploy S2D in a single Availability Zone the deployment becomes even more complicated because it is recommended that you deploy at least three cluster nodes and each node must reside in its own subnet due to some AWS networking restrictions that requires each cluster node reside in a different subnet. S2D was never designed to run in different subnets, which further complicates the solution in terms of client redirection.
“One item to note is that if you are familiar with Failover Clusters in the past, stretch clusters have been a very popular option over the years. There was a bit of a design change with the hyper-converged solution and it is based on resiliency. If you lose two nodes in a hyper-converged cluster, the entire cluster will go down. With this being the case, in a hyper-converged environment, the stretch scenario is not supported.”
In contrast, the SIOS DataKeeper solution fully supports Always On Availability Groups, and better yet – it can allow you to stretch your FCI across sites to give you the best HA/DR solution you could hope to achieve in terms of RTO/RPO. DataKeeper supports Availability Zones and DR configurations that cross cloud regions. In an Azure environment, DataKeeper also support Azure Site Recovery (ASR), giving you even more options for disaster recovery.
Further complicating any S2D deployment in AWS is the reliance on “local instance store” storage, AKA, non-persistent ephemeral disks.
“The best performance for storage can be achieved using I3 instances because they provide local instance store with NVMe and high network performance”
Reliance on ephemeral storage puts your data at risk any time a disk rebuilds, which can happen at any time, but always happens when an instance is stopped. If a disk is lost and a second disk is lost before the first disk rebuilds you are looking at complete data loss and a restore from backup. If someone accidentally stops all the nodes in your cluster your data will be lost! Even if you take care to only stop one node at a time if you are not paying attention and waiting for a disk to complete a rebuild after you stop the second node you will also experience complete data loss!
The SIOS DataKeeper solution is much more lenient. It supports any locally attached storage and as long as the hardware passes cluster validation, it is a supported cluster configuration. The block level replication solution has been working great ever since 1 Gbps was considered a fast LAN and a T1 WAN connection was considered a luxury.
SANless clustering is particularly interesting for cloud deployments. The cloud does not offer traditional shared storage options for clusters. So for users in the middle of a “lift and shift” to the cloud that want to take their clusters with them they must look at alternate storage solutions. For cloud deployments, SIOS is certified for Azure, AWS and Google and available in the relevant cloud marketplace. While there doesn’t appear to be anything blocking deployment of S2D based clusters in AWS or Google, there is a conspicuous lack of documentation or supportability statements from Microsoft for those platforms.
SIOS DataKeeper has been doing this since 1999. SIOS has heard all the feature requests, uncovered all the bugs, and has a rock solid solution for SANless clusters that is time tested and proven. While Microsoft S2D is a promising technology, as a 1st generation product I would wait until the dust settles and some of the feature gap closes before I would consider it for my business critical applications.
Yesterday evening Pacific Standard Time, Azure storage services experienced a service interruption across the United States, Europe and parts of Asia, which impacted multiple cloud services in these regions.
As part of a performance update to Azure Storage, an issue was discovered that resulted in reduced capacity across services utilizing Azure Storage, including Virtual Machines, Visual Studio Online, Websites, Search and other Microsoft services.
So what does this outage mean to those thinking about a cloud deployment? Global “interruptions” of this magnitude certainly cannot occur on any regular basis for any cloud provider that intends to remain in the cloud business, whether they are Microsoft, Amazon, Google or other. However, as a cloud architect or person responsible for a cloud deployment, you have a responsibility to your customer to have a “Plan B” in your back pocket in case the worst case scenario actually happens.
What exactly is a “Plan B”? Plan B involves having a documented procedure for recovering data and services in an alternate location in the event of a wide spread outage that impacts a cloud provider’s ability to deliver their service, despite deploying what you thought was a highly resilient cloud deployment designed to keep running even in the event of localized outages within a region, availability zone or fault domain.
At a high level you should be concerned about three things: Data Recovery, Application Recovery, and Client Access. There are many ways to address these concerns, some more automated than others and some with a better Recovery Time Objective (RTO) and Recovery Point Objective (RPO) than others.
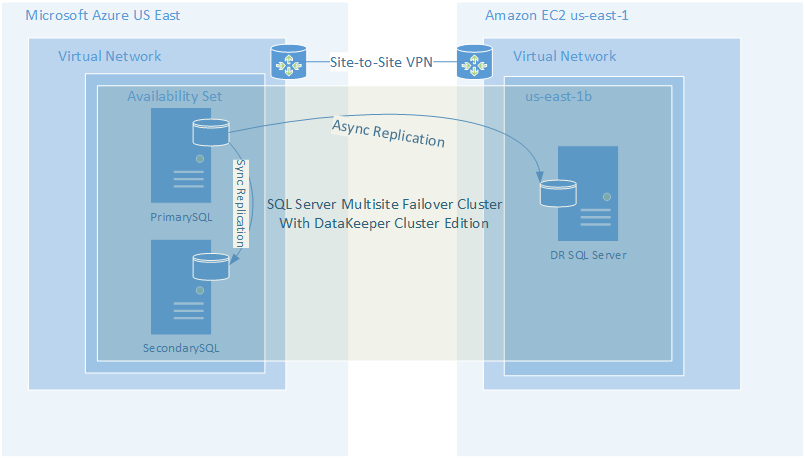
Figure 1 – Example of a Cloud-to-Cloud Multisite Cluster Configuration
Another alternative to the “cloud-to-cloud” replication model is of course utilizing your own datacenter as a disaster recovery site for your cloud deployment. The advantages of this is that you have physical ownership of your data, but of course now you are back in the business of managing a datacenter, which can negate some of the benefit of a pure cloud deployment.
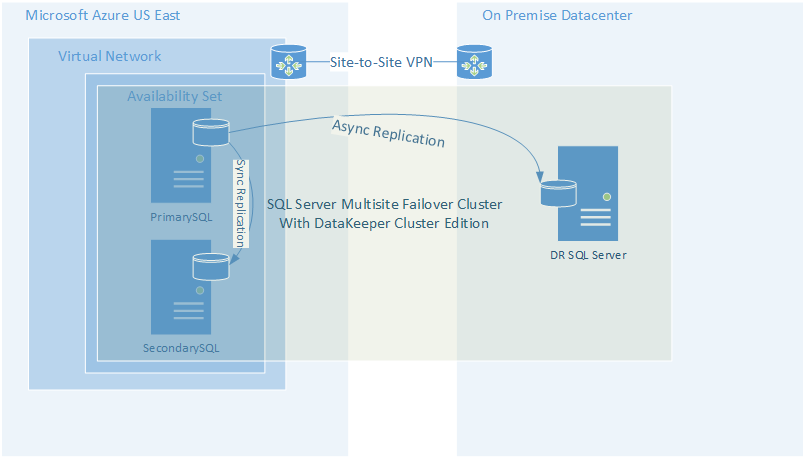
Figure 2 – Hybrid Cloud Deployment Model
If you are not ready to go full on cloud, you can still make use of the cloud as a disaster recovery site. This is probably the easiest and most cost effective way to implement an offsite datacenter for disaster recovery and to start taking advantage of what the cloud has to offer without fully committing to moving all your workloads into the cloud.
Figure 3 – Using the Cloud as a Disaster Recovery Site
The illustrations shown above make use of the host based replication solution called DataKeeper Cluster Edition to build multisite SQL Server clusters. However, DataKeeper can be used to keep any data in sync, either between different cloud providers or in the hybrid cloud model.
Microsoft is not alone in dealing with cloud outages as outages have impacted Google, Microsoft, Amazon, DropBox and many others just this year alone. Having a “Plan B” in place is a must have anytime you are relying on any cloud service.
Ever want to deploy a SQL Server cluster with some nodes in AWS and other nodes in Azure? Well, you are in luck! This article describes the process in great detail.
When you launch a new instance you only have two options for the OS storage: Standard or Provisioned IOPS. Both are EBS volumes persistent across reboots. Many instances come with a bunch of extra ephemeral drives attached, which are NOT persistent. I usually delete these ephemeral drives so I am not tempted to store data on them. You will have to add additional EBS volumes for additional persistent storage.
This article seems to indicate that you can launch AMI’s based on the “EC2 Instance Store”, which is NOT persistent, but I’ve never seen that option. All of my instances have always had root devices that are EBS based; I have not seen one that is not EBS based. I’m assuming they mean some of the instances in the Amazon Market Place may use non-persistent volumes. http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/RootDeviceStorage.html
You’ll see the root device when you launch the instance, like I highlighted below. As long as EBS is the root device you are good to go and can be sure your changes will persist across reboots.
As far as instance size, it will depend on the needs of the application. The good thing about EC2 is that if you provision an AMI that is under powered, you can go back and increase the instance size, though it does require a reboot. If IOPS are important, you will want to make sure you choose an instance that is EBS optimized. See this page for the instance details. http://aws.amazon.com/ec2/instance-types/#instance-details . You’ll see the first instance type which is EBS optimized is M1.large.
Read this guide for additional tips for optimal storage configuration. http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/EBSPerformance.html . One of the best tips for increased IOPS is to use multiple smaller EBS volumes and put them together in a RAID 0 on the Windows server. Because the EBS volumes are RAID1 on the backend, you are essentially deploying RAID 1+0 in your VM for optimal performance and availability.
In the old days if you wanted a guaranteed 4000 IOPS on EBS, you had to provision a minimum of a 400 GB vo0lume. Considering you pay per the GB, and provisioned IOPS are not cheap, if you only needed 100 GB of fast storage you were stuck paying for 300 GB of unused storage.
With this recent announcement Amazon has made it easier to get fast storage in smaller increments. Now if you want 4000 IOPS you can get that in EBS volumes as small as 133 GB up to 1 TB in size. Read the following press release for more information.
Deploying Your Business Critical SQL Server Apps on Amazon EC2
Amazon Web Services (AWS) and SIOS Technology Corp, an AWS Partner Network (APN) Technology Partner, invite you to attend this live webinar to learn how to optimize mission critical SQL Server deployments on Amazon EC2.
Learn how to take advantage of the cost benefits and flexibility of Amazon EC2 while maintaining protection with native Microsoft Windows Server Failover Clustering – all without shared storage.
Who should attend:
Solution Architects, Developer, Development Leads and other SQL Professionals
Presenters:
Miles Ward, Solutions Architect, Amazon Web Services
Tony Tomarchio, Director of Field Engineering, SIOS Technology Corp
I recently read an article entitled SQL Server 2012 AlwaysOn: High Availability database for cloud data centers where the author John Joyner makes a case for using AlwaysOn Availability Groups for SQL Server high availability in the cloud. I have been investigating AlwaysOn Availability Groups since it was available in pre-release versions of SQL Server 2012 and while it certainly has some valid uses (mostly in disaster recovery configurations), saying that it is a “new way to achieve HA SQL” glosses over many of the issues which make deploying AlwaysOn Availability Groups as a replacement for failover clusters simply not a viable option in many cases and not a good idea in the rest of the cases. In a response I wrote to the article I proposed that an AlwaysOn Multisite Clustering using the host based replication solution DataKeeper Cluster Edition is a much better alternative and I went ahead and explained why..
My original response to the article seems to have been deleted, so I decided to repost my response to the original article below:
There are a few things to consider with AlwaysOn Availability Groups. As you mention, “Microsoft announced support for some System Center 2012 SP1 applications to work with SQL AlwaysOn”, meaning that there are still applications that do not support AlwaysOn. In fact, there are a LOT of applications that do not support AlwaysOn Availability Groups, including any applications that use distributed transactions. And what about the other limitations, like not being able to keep MSDB, Master and other databases in sync? I blog about these limitations here.
I agree that SQL HA is important, however, the only way to get “High Availability” (meaning automatic recovery in the event of a failure) with AlwaysOn Availability Groups is by using synchronous mirroring. At PASS Summitt in Seattle earlier this month I sat in many different presentations on AlwaysOn and almost without fail the presenters talked about AlwaysOn in an asynchronous configuration. The reason being is that AlwaysOn synchronous replication has a SIGNIFICANT impact on the performance of your application. I have personally measured up to a 68% performance penalty with AlwaysOn Synchronous mirroring, and that was across a dedicated 10 Gbps LAN! I blog about this result here.
Unfortunately, in an asynchronous configuration you give up automatic failover, so you really are not getting HA, you are getting data protection, but certainly not the same RTO as you can expect from a traditional SQL failover cluster.
And then finally there is the cost to consider. SQL Server 2012 Enterprise is nothing to sneeze at. If you want to build a 2-node cluster and take advantage of readable secondaries and you are using a 2-socket, 16-core servers you are looking at shelling out close to $220k for SQL Server 2012 Enterprise licenses. I broke down the associated cost in my blog article here.
Don’t get me wrong, SQL Server 2012 AlwaysOn Availability Groups can solve many problems, but I would not categorize the asynchronous configuration required in most cloud deployments as an HA alternative. Many people are overlooking the other “AlwaysOn”, AlwaysOn Failover Clusters. New features of SQL Server AlwaysOn Failover Clusters, including enhanced support for cross subnet multisite clusters, will give you a true HA solution and overcomes all of the limitations I describe above. Of course in a pure cloud solution you may not be able to integrate with array based replication to support multisite clusters, but you can always use host based replication solutions such as SteelEye DataKeeper Cluster Edition to build multisite clusters in public or private clouds and in your own physical data center and you can do this with SQL Server 2008 through 2012 AND it works on SQL Server Standard edition as well as Enterprise.
Have you done any testing with AlwaysOn Availability Groups in a HA configuration? If so I’d be curious to know if you measured the overhead associated with synchronous replication in your environment.