With the introduction of Windows Server 2016 Datacenter Edition a new feature called Storage Spaces Direct (S2D) was introduced. At a very high level, this solution allows you to pool together locally attached storage and present it to the cluster as a CSV for use in a Scale Out File Server, which can then be accessed over SMB 3 and used to hold cluster data such as Hyper-V VMDK files. This can also be configured in a hyper-converged (HCI) fashion such that the application and data can all run on the same set of servers. This is a grossly over-simplified description, but for details, you will want to look here.
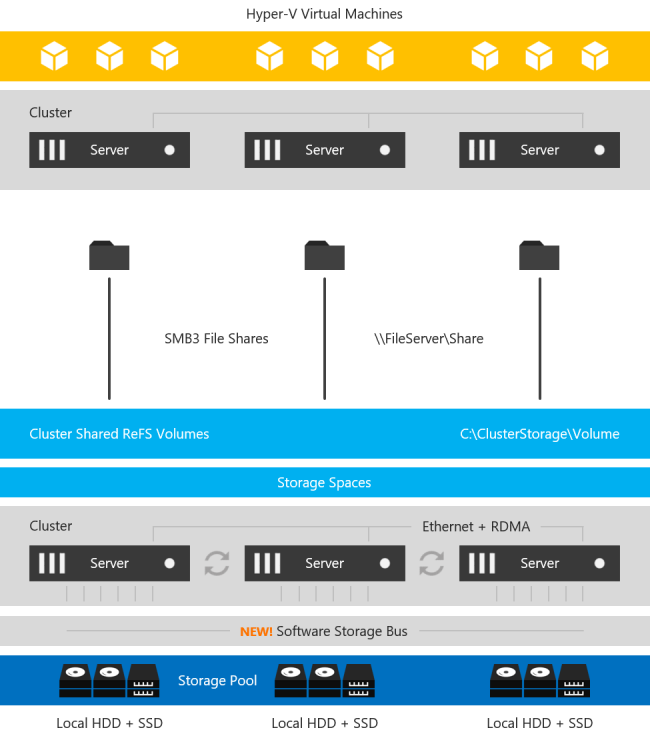
Image taken from https://docs.microsoft.com/en-us/windows-server/storage/storage-spaces/storage-spaces-direct-overview
The main use case targeted is hyper-converged infrastructure for Hyper-V deployments. However, there are other use cases, including leveraging this SMB storage to store SQL Server Data to be used in a SQL Server Failover Cluster Instance
Why would anyone want to do that? Well, for starters you can now build a highly available 2-node SQL Server Failover Cluster Instance (FCI) with SQL Server Standard Edition, without the need for shared storage. Previously, if you wanted HA without a SAN you pretty much were driven to buy SQL Server Enterprise Edition and make use of Always On Availability Groups or purchase SIOS DataKeeper and leverage the 3rd party solution which lets you build SANless clusters with any version of Windows or SQL Server. SQL Server Enterprise Edition can really drive up the cost of your project, especially if you were only buying it for the Availability Groups feature.
In addition to the cost associated with Availability Groups, there are a number of other technical reasons why you might prefer a Failover Cluster over an AG. Application compatibility, instance vs. database level protection, large number of databases, DTC support, trained staff, etc., are just some of the technical reasons why you may want to stick with a Failover Cluster Instance.
Microsoft lists both the SIOS DataKeeper solution and the S2D solution as two of the supported solutions for SQL Server FCI in their documentation here.

When comparing the two solutions, you have to take into account that SIOS has been allowing you to build SANless Clusters since 1999, while the S2D solution is still in its infancy. Having said that, there are bound to be some areas where S2D has some catching up to do, or simply features that they will never support simply due to the limitations with the technology.
Have a look at the following table for an overview of some of the things you should consider before you choose your SANless cluster solution.

If we go through this chart, we see that SIOS DataKeeper clearly has some significant advantages. For one, DataKeeper supports a much wider range of platforms, going all the way back to Windows Server 2008 R2 and SQL Server 2008 R2. The S2D solution only supports the latest releases of Windows and SQL Server 2016/2017. S2D also requires the Datacenter Edition of Windows, which can add significantly to the cost of your deployment. In addition, SIOS delivers the ONLY HA/DR solution for SQL Server on Linux that works both on-prem and in the cloud.
I’ve been talking to a lot of customers recently who are reporting some performance issues with S2D. When I tested S2D vs. DataKeeper about a year ago I didn’t see any significant differences in performance, but I did see S2D used about 2x the amount of CPU resources under the same load. This probably has to do with the high hardware requirements associated with S2D such as RDMA enabled networking and available Flash Storage, typically only available in the most expensive cloud based images.
“We recommend the I3 instance size because it satisfies the S2D hardware requirements and includes the largest and fastest instance store devices available.”
But beyond the cost and platform limitations, I think the most glaring gap comes when we start to consider that S2D does not support Availability Zones or disaster recovery configurations such as multi-site clusters or Azure Site Recovery (ASR). Allan Hirt, SQL Server Cluster guru and fellow Microsoft Cloud and Datacenter Management MVP, recently posted about this S2D limitation. In his article Revisiting Storage Spaces Direct and SQL Server FCIs Allan points out that due to the lack of support for stretching S2D clusters across sites or including an S2D based cluster as a leg in an Always On Availability Group, the best option for DR in the S2D scenario is log shipping! This even includes replicating across Availability Zones in either Azure or AWS.
Microsoft does not make it clear in their documentation, but Microsoft’s own PM for High Availability and Storage makes it perfectly clear in the Microsoft forums.
AWS also documents S2D’s lack of Availability Zone support…
“Each cluster node must be deployed in a different subnet. This architecture will be deployed into a single availability zone because Microsoft does not currently support stretch cluster with Storage Spaces Direct. ” – AWS Documentation on S2D
Deploying S2D cluster nodes within the same Availability Zone defeats the purpose of failover clustering and the deployment does not qualify for the AWS 99.99% SLA. Even if you wanted to deploy S2D in a single Availability Zone the deployment becomes even more complicated because it is recommended that you deploy at least three cluster nodes and each node must reside in its own subnet due to some AWS networking restrictions that requires each cluster node reside in a different subnet. S2D was never designed to run in different subnets, which further complicates the solution in terms of client redirection.
You can also find this statement in Disaster Recovery Scenarios for Hyper-Converged Infrastructure | Microsoft Docs
“One item to note is that if you are familiar with Failover Clusters in the past, stretch clusters have been a very popular option over the years. There was a bit of a design change with the hyper-converged solution and it is based on resiliency. If you lose two nodes in a hyper-converged cluster, the entire cluster will go down. With this being the case, in a hyper-converged environment, the stretch scenario is not supported.”
https://docs.microsoft.com/en-us/windows-server/storage/storage-spaces/storage-spaces-direct-disaster-recovery
In contrast, the SIOS DataKeeper solution fully supports Always On Availability Groups, and better yet – it can allow you to stretch your FCI across sites to give you the best HA/DR solution you could hope to achieve in terms of RTO/RPO. DataKeeper supports Availability Zones and DR configurations that cross cloud regions. In an Azure environment, DataKeeper also support Azure Site Recovery (ASR), giving you even more options for disaster recovery.
Further complicating any S2D deployment in AWS is the reliance on “local instance store” storage, AKA, non-persistent ephemeral disks.
“The best performance for storage can be achieved using I3 instances because they provide local instance store with NVMe and high network performance”
Reliance on ephemeral storage puts your data at risk any time a disk rebuilds, which can happen at any time, but always happens when an instance is stopped. If a disk is lost and a second disk is lost before the first disk rebuilds you are looking at complete data loss and a restore from backup. If someone accidentally stops all the nodes in your cluster your data will be lost! Even if you take care to only stop one node at a time if you are not paying attention and waiting for a disk to complete a rebuild after you stop the second node you will also experience complete data loss!
The rest of this chart is pretty self explanatory. It basically consist of a list hardware, storage and networking requirements that must be met before you can deploy an S2D cluster. An exhaustive list of S2D requirements is maintained here. https://docs.microsoft.com/en-us/windows-server/storage/storage-spaces/storage-spaces-direct-hardware-requirements
The SIOS DataKeeper solution is much more lenient. It supports any locally attached storage and as long as the hardware passes cluster validation, it is a supported cluster configuration. The block level replication solution has been working great ever since 1 Gbps was considered a fast LAN and a T1 WAN connection was considered a luxury.
SANless clustering is particularly interesting for cloud deployments. The cloud does not offer traditional shared storage options for clusters. So for users in the middle of a “lift and shift” to the cloud that want to take their clusters with them they must look at alternate storage solutions. For cloud deployments, SIOS is certified for Azure, AWS and Google and available in the relevant cloud marketplace. While there doesn’t appear to be anything blocking deployment of S2D based clusters in AWS or Google, there is a conspicuous lack of documentation or supportability statements from Microsoft for those platforms.
SIOS DataKeeper has been doing this since 1999. SIOS has heard all the feature requests, uncovered all the bugs, and has a rock solid solution for SANless clusters that is time tested and proven. While Microsoft S2D is a promising technology, as a 1st generation product I would wait until the dust settles and some of the feature gap closes before I would consider it for my business critical applications.
