Yesterday morning I opened my Twitter feed to find that many people were impacted by an Azure outage. When I tried to access the resource page that described the outage and the current resources impacted even that page was unavailable. @AzureSupport was providing updates via Twitter.
The original update from @AzureSupport came in at 7:12 AM EDT
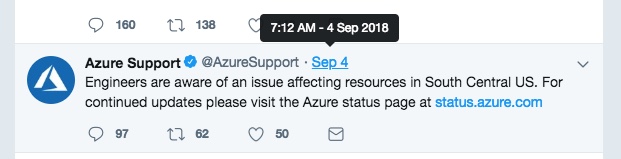
Looking back on the Twitter feed it seems as if the problem initially began an hour or two before that.
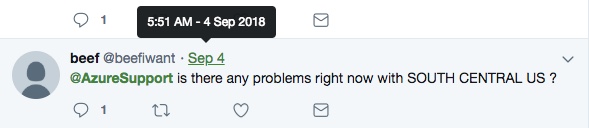
It quickly became apparent that the outages had a wider spread impact than just the SOUTH CENTRAL US region as originally reported. It seems as if services that relied on Azure Active Directory could have been impacted as well and customers trying to provision new subscriptions were having issues.

And 24 hours later the problem has not been completely resolved and it according to the last update this morning…


So what could you have done to minimize the impact of this outage? No one can blame Microsoft for a natural disaster such as a lightning strike. But at the end of the day if your only disaster recovery plan is to call, tweet and email Microsoft until the issue is resolved, you just received a rude awakening. IT IS UP TO YOU to ensure you have covered all the bases when it comes to your disaster recovery plan.
While the dust is still settling on exactly what was impacted and what customers could have done to minimize the downtime, here are some of my initial thoughts.
Availability Sets (Fault Domains/Update Domains) – In this scenario, even if you built Failover Clusters, or leveraged Azure Load Balancers and Availability Sets, it seems the entire region went offline so you still would have been out of luck. While it is still recommended to leverage Availability Sets, especially for planned downtime, in this case you still would have been offline.
Availability Zones – While not available in the SOUTH CENTRAL US region yet, it seems that the concept of Availability Zones being rolled out in Azure could have minimized the impact of the outage. Assuming the lightning strike only impacted one datacenter, the other datacenter in the other Availability Zone should have remained operational. However, the outages of the other non-regional services such as Azure Active Directory (AAD) seems to have impacted multiple regions, so I don’t think Availability Zones would have isolated you completely.
Global Load Balancers, Cross Region Failover Clusters, etc. – Whether you are building SANLess clusters that cross regions, or using global load balancers to spread the load across multiple regions, you may have minimized the impact of the outage in SOUTH CENTRAL US, but you may have still been susceptible to the AAD outage.
Hybrid-Cloud, Cross Cloud – About the only way you could guarantee resiliency in a cloud wide failure scenario such as the one Azure just experienced is to have a DR plan that includes having realtime replication of data to a target outside of your primary cloud provider and a plan in place to bring applications online quickly in this other location. These two locations should be entirely independent and should not rely on services from your primary location to be available, such as AAD. The DR location could be another cloud provider, in this case AWS or Google Cloud Platform seem like logical alternatives, or it could be your own datacenter, but that kind of defeats the purpose of running in the cloud in the first place.
Software as a Service – While Software as service such as Azure Active Directory (ADD), Azure SQL Database (Database-as-Service) or one of the many SaaS offerings from any of the cloud providers can seem enticing, you really need to plan for the worst case scenario. Because you are trusting a business critical application to a single vendor you may have very little control in terms of DR options that includes recovery OUTSIDE of the current cloud service provider. I don’t have any words of wisdom here other than investigate your DR options before implementing any SaaS service, and if recovery outside of the cloud is not an option than think long and hard before you sign-up for that service. Minimally make the business stake owners aware that if the cloud service provider has a really bad day and that service is offline there may be nothing you can do about it other than call and complain.
I think in the very near future you will start to hear more and more about cross cloud availability and people leveraging solutions like SIOS DataKeeper to build robust HA and DR strategies that cross cloud providers. Truly cross cloud or hybrid cloud models are the only way to truly insulate yourself from most conceivable cloud outages.
If you were impacted from this latest outage I’d love to hear from you. Tell me what went down, how long you were down, and what you did to recover. What are you planning to do so that in the future your experience is better?

[…] disasters, even popular service providers like Azure can suffer an […]
[…] One of the challenges you will face when running SQL Server 2008/2008 R2 in Azure is ensuring high availability. On premises you may be running a SQL Server Failover Cluster (FCI) instance for high availability, or possibly you are running SQL Server in a virtual machine and are relying on VMware HA or a Hyper-V cluster for availability. When moving to Azure, none of those options are available. Downtime in Azure is a very real possibility that you must take steps to mitigate. […]
[…] I wrote during the last major cloud outage, if you are running business critical workloads in the cloud, […]
[…] One of the challenges you will face when running SQL Server 2008/2008 R2 in Azure is ensuring high availability. On premises you may be running a SQL Server Failover Cluster (FCI) instance for high availability, or possibly you are running SQL Server in a virtual machine and are relying on VMware HA or a Hyper-V cluster for availability. When moving to Azure, none of those options are available. Downtime in Azure is a very real possibility that you must take steps to mitigate. […]
[…] If Azure suffers an outage, data could become temporarily unavailable, causing delay or loss of day-to-day business […]