Introduction
The topic of mixing SQL Server Failover Cluster Instances (FCI) with Always On Availability Groups (AG) is pretty well documented. However, most of the available documentation documents configurations that assume the SQL Server FCI portion of the solution utilizes shared storage. What if I want to build a SANless SQL Server FCI using Storage Spaces Direct (S2D), can I still add a SQL Server AG to the mix? Unfortunately, the answer to this question is no. As of today, this combination of S2D based SQL Server FCI and Always On AG is not supported. I previously blogged about this S2D limitation here.
However, the good news is you CAN build a SANless SQL Server FCI with SIOS DataKeeper and still leverage Always On AG for things like readable secondaries. You still have to abide by the same rules that apply when mixing traditional SAN based SQL Server FCI and Always On AGs, but other than that it is exactly the same….mostly.
DataKeeper Synchronous replication is commonly used between nodes in the same data center or cloud region, but you may want to replicate asynchronously to an additional node in a different region for disaster recovery. In this case, if you ever do have to bring the DR node online after an unexpected failure, you will have to scrap the Always On AG configurations and reconfigure them. This requirement is very similar to to what Microsoft published here in regards to restoring asynchronous snapshots of SQL Server Always On AGs running inside VMs.
Availability Groups
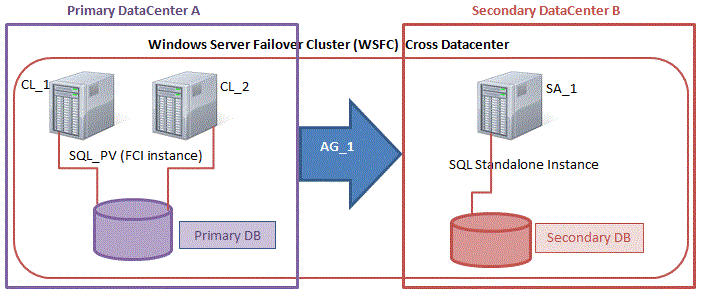
Essentially, a SANLess SQL Server FCI w/DataKeeper looks like a single instance of SQL Server as far as the Always On Availability Group Wizard is concerned. The configuration of the Always On AG is exactly the same as if you were creating just an Always On AG between two Standalone (non-clustered) SQL Server instances.
The real confusion arise in the fact that in this configuration all the servers reside in the same failover cluster, but the SQL Server FCI is only configured to run only on the cluster nodes where SQL Server was installed as a Clustered SQL Server Instance. The other nodes are in the same cluster, but SQL is installed on those nodes as a Standalone SQL Server Instance, not a Clustered Instance. It’s a bit confusing, but what is happening is that Always On AG’s leverage the WSFC quorum model and listeners, so all the AG Replicas need to reside in the same WSFC, even though they typically do not run clustered instances of SQL Server. If you are completely confused that is okay, most people are confused when they first try to wrap their head around this hybrid configuration.
The real benefit in a configuration like this is that a SQL Server FCI can be a better and more cost effective (more on this later*) HA solution than Always On AG in many circumstances, but it lacks the ability to offer a readable secondary replica. Adding an Always On AG readable secondary replica becomes a viable option to address this need. And using SIOS DataKeeper eliminates the need for a SAN for the SQL Server FCI, which opens up the possibility of configuring SQL Server FCIs where nodes reside in different data center, which also means support for SQL Server FCI’s that span Availability Zones in both Azure and AWS.
Please note that pictured below is just one possible configuration. Multiple FCI cluster nodes, multiple AGs and multiple Replicas are all supported. You are only limited by the limits imposed by your version of SQL Server.
This article seems to document the setup steps pretty well. Of course, instead of shared storage for the SQL FCI, you will use SIOS DataKeeper to build the FCI as I document here.
Basic Availability Groups
As of SQL Server 2016 a scaled down “Basic Availability Groups” became available in SQL Server Standard Edition, making this configuration possible even in SQL Server Standard Edition. Basic AGs are limited to a single database per Availability Group, a Single Replica (2-nodes). However, they do not support a readable secondary replica so their use cases in this hybrid configuration are very limited.
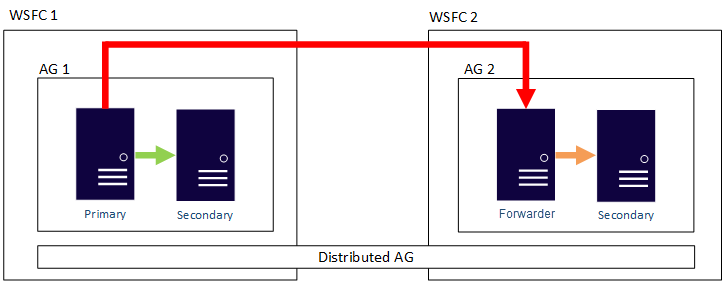
Distributed Availability Groups
Distributed AGs were introduced in SQL Server 2016 are also supported in this hybrid configuration. Distributed AGs are very similar to regular AGs, but the Replicas do not need to reside in the same cluster, or even in the same Windows Domain. Microsoft documents the the main use cases of Distributed Availability Groups as follows:
- Disaster recovery and easier multi-site configurations
- Migration to new hardware or configurations, which might include using new hardware or changing the underlying operating systems
- Increasing the number of readable replicas beyond eight in a single availability group by spanning multiple availability groups
Summary
If you like the idea of SQL Server FCIs for high availability, but want the flexibility of read-only secondary replicas, this hybrid solution might just be the thing you are looking for. Traditional SAN baseds SQL Server FCIs, and even Storage Spaces Direct (S2D) based FCIs, limit you to a single data center. SIOS DataKeeper frees you from the limits of your SAN and enables configurations such as SQL Server FCI that span Availability Zones or Cloud Regions. It also eliminates the reliance on the SAN, allowing you to leverage locally attached high speed storage devices without giving up your SQL Server FCI.
* How to Save Money
Earlier I promised I would tell you how to save money by doing this all with SQL Server Standard Edition. If you can live with readable replicas that are point in time based snapshots, you can skip Always On AGs completely and just use the SIOS DataKeeper target side snapshot feature to periodically take an application consistent snapshot of the volumes on the target server without impacting ongoing replication or availability. Here’s how…

Create a 2-node SQL Server FCI with SQL Server Standard Edition and save a boatload of money on SQL licenses, but yet still replicate the data to a 3rd node outside the cluster for reporting or DR purposes. If you take a snapshot of the volumes on this third server these snapshots are read-right accessible, so you can mount those databases from a standalone instance of SQL Server to run month end reports, copy to archives, or you might even want to use those snapshot to quickly and easily update your QA and Test/Dev environments with the latest SQL data.
I hope you found this helpful and informative. As always, if you have questions, add them here or reach me on Twitter @daveberm

Can you suggest how to replicate from primart DC to secondary DC I have similar configuration but two cluster with 2 nodes in each DC. All with Sql-Server Standard.
If you have SQL 2016 you could use a Basic Availability Group to replicate SQL databases between clusters. Otherwise you might have to look into Database Mirroring or Log Shipping.
Hi Dave, thank you so much for the article! I have a question if we have a SQL server WIndows 2008 running SQL 2008 in SQL 2000 compatibility mode with 2 nodes and 1 sql instance cluster, what is the best way to migrate this into azure without a headache creating a cluster in azure?
I would recommend biting the bullet and creating a cluster in Azure. Otherwise, you could simply build a standalone instance in Azure and then do a backup and restore of your databases to the standalone instance.
Hi Dave, apologies for the comment so long after publishing this post but Google has just sent me here!
I have a 2 node FCI (with the requisite WSFC underneath of course) in our primary Data Center. We have a new standalone box in our DR data center we want to utilise (for DR, not HA) by creating an AG between the FCI and standalone box. This standalone will not be part of the WSFC due to Zerto/RDMs incompatibility. It also will *not* be used for reporting/reading. So, essentially this is a read-scale replica (albeit without the readability) correct? And because we’re not reading from it, we don’t need an AG listener?
Our stakeholders are aware of the limitations on the above proposal re manual failover to the secondary AG replica and the probability of some data loss from an unplanned failover (RTO/RPO still being defined).
Thanks,
Richard.
My understanding of AGs is that all the nodes need to be in the same “cluster”. This doesn’t mean you need to extend your SQL Server FCI to the DR node, but it DOES have to be a member of the base cluster. Once you do that you should be able to create an async AG between the 2-node FCI and this standalone instance of SQL Server.