If you have been following my blog, you probably know that I write a lot of step-by-step guides for building SQL Server Failover Cluster Instances (FCI) on Azure, from SQL Server 2008 through the lastest. Here are some links to get you started, but really there is very little difference in the configuration between the different versions of Windows and SQL Server, so I think you will be able to figure it out regardless of what versions you use.
However, that article/video only addresses SQL Server 2016 and later. The good news is that most of that guidance can be applied to SQL Server 2008/2012/2014. Until I have time to do a proper step-by-step guide I wanted to jot down some basic notes, more as a reminder to myself, but you might find this information useful as well in the meantime.
The steps below assume you have already created a SQL Server FCI in Azure and clustered the DTC resource. Reference the guides above for the details on those steps. The steps below really just detail the load balancer configuration required in Azure to make this work.
Create Load Balancer for MSDTC
The MSDTC resource will require its own load balancer. Instead of creating a new load balancer, we will add a new frontend to the load balancer that should already be configured for the SQL Server FCI. Of course this frontend IP address should match the cluster IP address associated with the clustered MSDTC resource.
For the backend pool just reuse the existing pool that you created that contains the SQL cluster nodes.
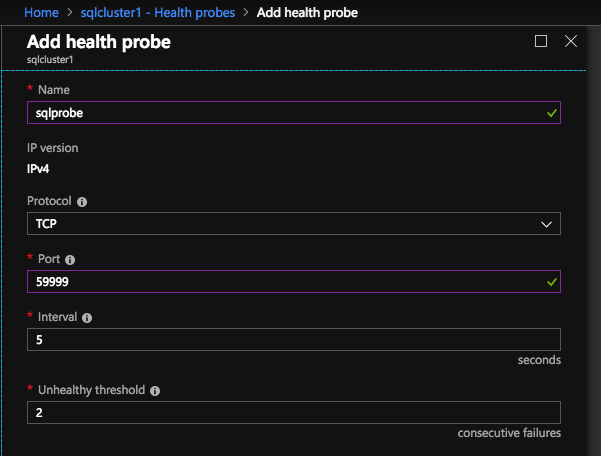
You will need to create a new health probe dedicated to the MSDTC resource. The port you use has to be different than the one you used for the SQL resource, so don’t use 59999. Instead maybe use something like 49999.
The final step is to create the load balancing rule for MSDTC. Create a new rule and reference the MSDTC frontend that we just created and the existing backend. Next we need to create a new load balancing rule. Since MSDTC uses ephemeral ports, which is a big range of ports, when you create the rule you have to select the box that says “HA Ports”. And finally make sure Direct Server Return is enabled.
Update MSDTC Cluster IP Resource
Just like our SQL Server Cluster IP address, we need to run a Powershell command that will for the MSDTC cluster IP resource to respond to the health probe we just created that probes port 49999. It also sets the subnet mask of that MSDTC cluster IP address to 255.255.255.255 to avoid IP address conflicts with the load balancer frontend we setup that shares the same address.
# Define variables $ClusterNetworkName = “”
# the cluster network name (Use Get-ClusterNetwork on Windows Server 2012 of higher to find the name of the MSDTC resource) $IPResourceName = “”
# the IP Address resource name of the MSDTC resource $ILBIP = “”
# the IP Address of the Internal Load Balancer (ILB) and MSDTC resource
Import-Module FailoverClusters
# If you are using Windows Server 2012 or higher:
Get-ClusterResource $IPResourceName | Set-ClusterParameter -Multiple @{Address=$ILBIP;ProbePort=49999;SubnetMask="255.255.255.255";Network=$ClusterNetworkName;EnableDhcp=0}
# If you are using Windows Server 2008 R2 use this:
#cluster res $IPResourceName /priv enabledhcp=0 address=$ILBIP probeport=59999 subnetmask=255.255.255.255
Confirm it is working!
You can use DTCPing or go into Component Services and look under Computers>My Computers>Distributed Transaction Coordinator where you should see a local DTC and a clustered DTC. Any distributed transactions should appear in the clustered DTC, not the local DTC. Check out this video for an example of how to create a distributed transaction for testing.
Next Steps
This is a quick and dirty guide, but for the experienced user it should get your MSDTC resource up and running in Azure. I’ll be publishing a detailed step-by-step guide in the near future. In the meantime, if you get stuck don’t hesitate to reach out to me on Twitter @daveberm
If you are reading this article you probably are still using SQL Server 2008/2008 R2 and want to take advantage of the extended security updates that Microsoft is offering if you move your SQL Server 2008/2008 R2 into Azure. I previously wrote about this topic in this blog post.
You may be wondering how to make sure your SQL Server instance remains highly available once you make the move to Azure. Today, most people have business critical SQL Server 2008/2008 R2 configured as a clustered instance (SQL Server FCI) in their data center. When looking at Azure you have probably come to the realization that due to the lack of shared storage it might seem that you can’t bring your SQL Server FCI to the Azure cloud. However, that is not the case thanks to SIOS DataKeeper.
SIOS DataKeeper enables you to build a SQL Server FCI in Azure, AWS, Google Cloud, or anywhere else where shared storage is not available or where you wish to configure multi-site clusters where shared storage doesn’t make sense. DataKeeper has been enabling SANless clusters for WIndows and Linux since 1999. Microsoft documents the use of SIOS DataKeeper for SQL Server FCI in their documentation: High availability and disaster recovery for SQL Server in Azure Virtual Machines.
I’ve written about SQL Server FCI’s running in Azure before, but I never published a Step-by-Step Guide specific to SQL Server 2008/2008 R2. The good news is that it works just as great with SQL 2008/2008 R2 as it does with SQL 2012/2014/2016/2017 and the soon to be released 2019. Also, regardless of the version of Windows Server (2008/2012/2016/2019) or SQL Server (2008/2012/2014/2016/2017) the configuration process is similar enough that this guide should be sufficient enough to get you through any configurations.
If your flavor of SQL or Windows is not covered in any of my guides, don’t be afraid to jump in and build a SQL Server FCI and reference this guide, I think you will figure out any differences and if you ever get stuck just reach out to me on Twitter @daveberm and I’ll be glad to give you a hand.
This guide uses SQL Server 2008 R2 with Windows Server 2012 R2. As of the time of this writing I did not see an Azure Marketplace image of SQL 2008 R2 on Windows Server 2012 R2, so I had to download and install SQL 2008 R2 manually. Personally I prefer this combination, but if you need to use Windows Server 2008 R2 or Windows 212 that is fine. If you use Windows Server 2008 R2 don’t forget to install the kb3125574 Convenience Rollup Update for Windows Server 2008 R2 SP1. Or if you are stuck with Server 2012 (not R2) you need the Hotfix in kb2854082.
Don’t be fooled by this article that says you must install kb2854082 on your SQL Server 2008 R2 instances. If you start searching for that update for Windows Server 2008 R2 you will find that only the version for Server 2012 is available. That particular hotfix for Server 2008 R2 is instead included in the rollup Convenience Rollup Update for Windows Server 2008 R2 SP1.
Provision Azure Instances
I’m not going to go into great detail here with a bunch of screenshots, especially since the Azure Portal UI tends to change pretty frequently, so any screenshots I take will get stale pretty quickly. Instead, I will just cover the important topics that you should be aware of.
Fault Domains or Availability Zones?
In order to ensure your SQL Server instances are highly available, you have to make sure your cluster nodes reside in different Fault Domains (FD) or in different Availability Zones (AZ). Not only do your instances need to reside in different FDs or AZs, but your File Share Witness (see below) also needs to reside in a FD or AZ that is different than that one your cluster nodes reside in.
Here is my take on it. AZs are the newest Azure feature, but they are only supported in a handful of regions so far. AZs give you a higher SLA (99.99%) then FDs (99.95%), and protect you against the kind of cloud outages I describe in my post Azure Outage Post-Mortem. If you can deploy in a region that supports AZs then I recommend you use AZs.
In this guide I used AZs which you will see when you get to the section on configuring the load balancer. However, if you use FDs everything will be exactly the same, except the load balancer configuration will reference Availability Sets rather than Availability Zones.
What is a File Share Witness you ask?
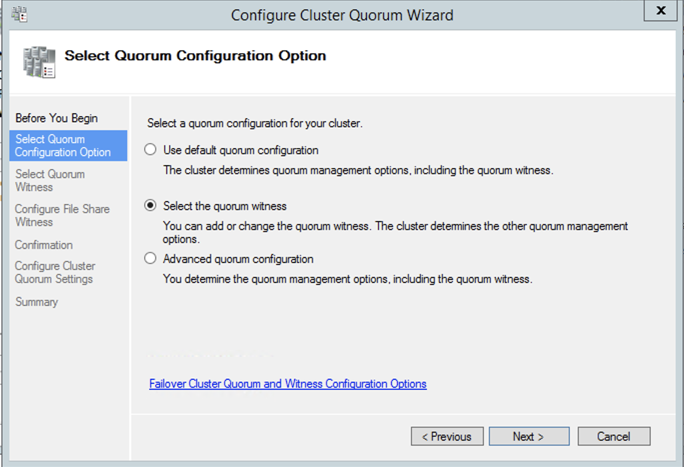
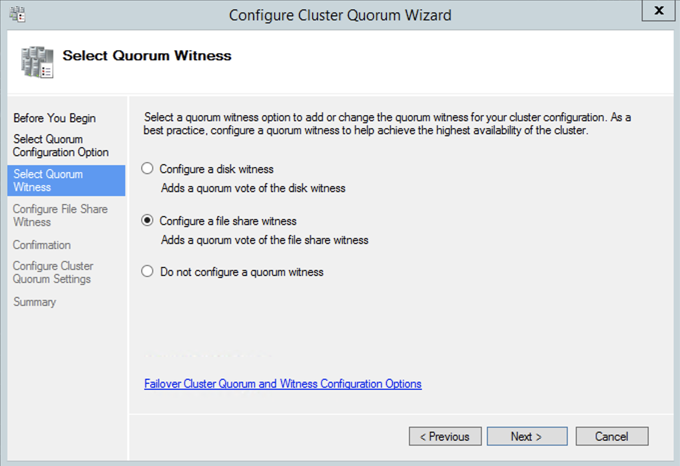
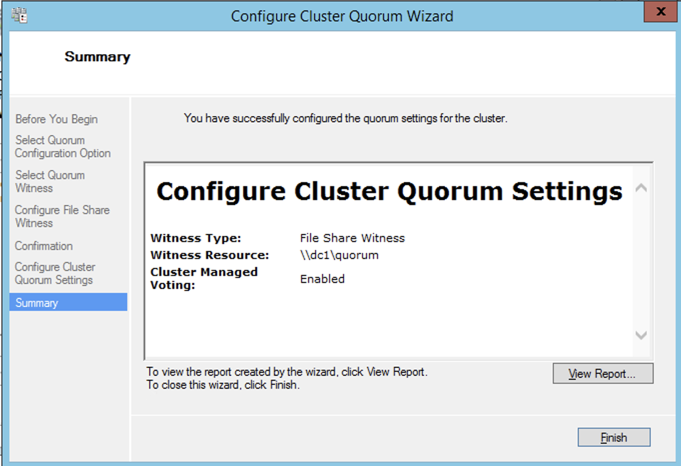
Without going into great detail, Windows Server Failover Clustering (WSFC) requires you configure a “Witness” to ensure failover behaves properly. WSFC supports three kinds of witnesses: Disk, File Share, Cloud. Since we are in Azure a Disk Witness is not possible. Cloud Witness is only available with Windows Server 2016 and later, so that leaves us with a File Share Witness. If you want to learn more about cluster quorums check out my post on the Microsoft Press Blog, From the MVPs: Understanding the Windows Server Failover Cluster Quorum in Windows Server 2012 R2
Add storage to your SQL Server instances
As you provision your SQL Server instances you will want to add additional disks to each instance. Minimally you will need one disk for the SQL Data and Log file, one disk for Tempdb. Whether or not you should have a seperate disk for log and data files is somewhat debated when running in the cloud. On the back end the storage all comes from the same place and your instance size limits your total IOPS. In my opinion there really isn’t any value in separating your log and data files since you cannot ensure that they are running on two physical sets of disks. I’ll leave that for you to decide, but I put log and data all on the same volume.
Normally a SQL Server 2008 R2 FCI would require you to put tempdb on a clustered disk. However, SIOS DataKeeper has this really nifty feature called a DataKeeper Non-Mirrored Volume Resource. This guide does not cover moving tempdb to this non-mirrored volume resource, but for optimal performance you should do this. There really is no good reason to replicate tempdb since it is recreated upon failover anyway.
As far as the storage is concerned you can use any storage type, but certainly use Managed Disks whenever possible. Make sure each node in the cluster has the identical storage configuration. Once you launch the instances you will want to attach these disks and format them NTFS. Make sure each instance uses the same drive letters.
Networking
It’s not a hard requirement, but if at all possible use an instance size that supports accelerated networking. Also, make sure you edit the network interface in the Azure portal so that your instances use a static IP address. For clustering to work properly you want to make sure you update the settings for the DNS server so that it points to your Windows AD/DNS server and not just some public DNS server.
Security
By default, the communications between nodes in the same virtual network are wide open, but if you have locked down your Azure Security Group you will need to know what ports must be open between the cluster nodes and adjust your security group. In my experience, almost all the issues you will encounter when building a cluster in Azure are either caused by blocked ports.
DataKeeper has some some ports that are required to be open between the clustered instance. Those ports are as follows: UDP: 137, 138 TCP: 139, 445, 9999, plus ports in the 10000 to 10025 range
In addition, the Load Balancer described later will use a probe port that must allow inbound traffic on each node. The port that is commonly used and described in this guide is 59999.
And finally if you want your clients to be able to reach your SQL Server instance you want to make sure your SQL Server port is open, which by default is 1433.
Remember, these ports can be blocked by the Windows Firewall or Azure Security Groups, so to be sure to check both to ensure they are accessible.
Join the Domain
A requirement for SQL Server 2008 R2 FCI is that the instances must reside in the same Windows Server Domain. So if you have not done so, make sure you have joined the instances to your Windows domain
Local Service Account
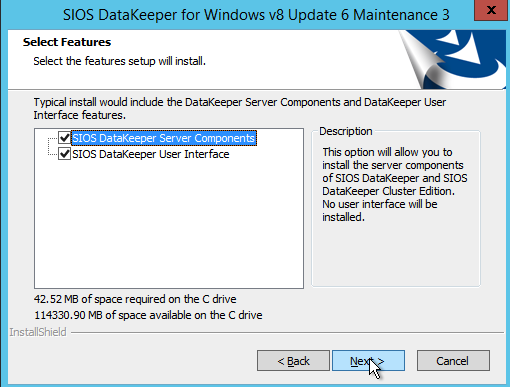
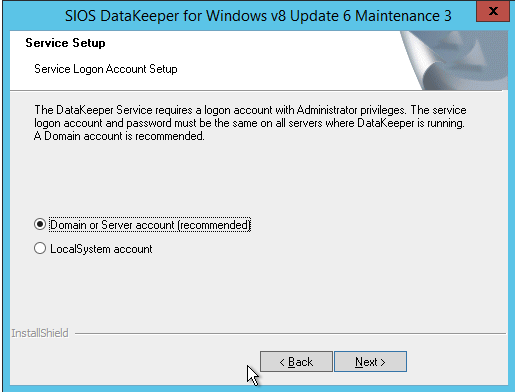
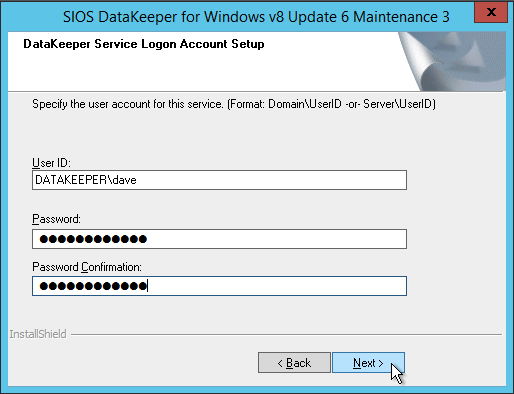
When you install DataKeeper it will ask you to provide a service account. You must create a domain user account and then add that user account to the Local Administrators Group on each node. When asked during the DataKeeper installation, specify that account as the DataKeeper service account. Note – Don’t install DataKeeper just yet!
Domain Global Security Groups
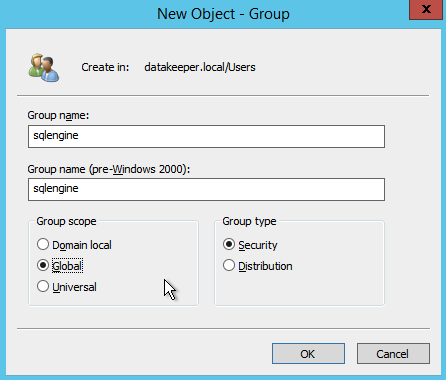
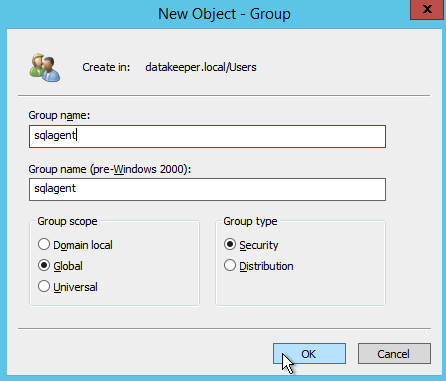
When you install SQL 2008 R2 you will be asked to specify two Global Domain Security Groups. You might want to look ahead at the SQL install instructions and create those groups now. You will also want to create a domain user account and place them in each of these security accounts. You will specify this account as part of the SQL Server Cluster installation.
Other Pre-Requisites
You must enable both Failover Clustering and .Net 3.5 on each instance of the two cluster instances. When you enable Failover Clustering, also be sure to enable the optional “Failover Cluster Automation Server” as it is required for a SQL Server 2008 R2 cluster in Windows Server 2012 R2.
Create the Cluster and DataKeeper Volume Resources
We are now ready to start building the cluster. The first step is to create the base cluster. Because of the way Azure handles DHCP, we MUST create the cluster using Powershell and not the Cluster UI. We use Powershell because it will let us specify a static IP address as part of the creation process. If we used the UI it would see that the VMs use DHCP and it will automatically assign a duplicate IP address, so we we want to avoid that situation by using Powershell as shown below.
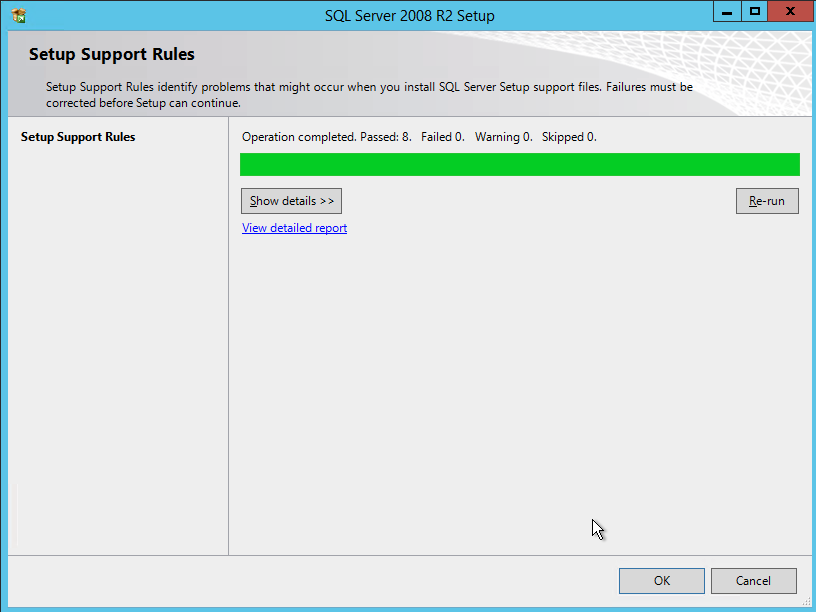
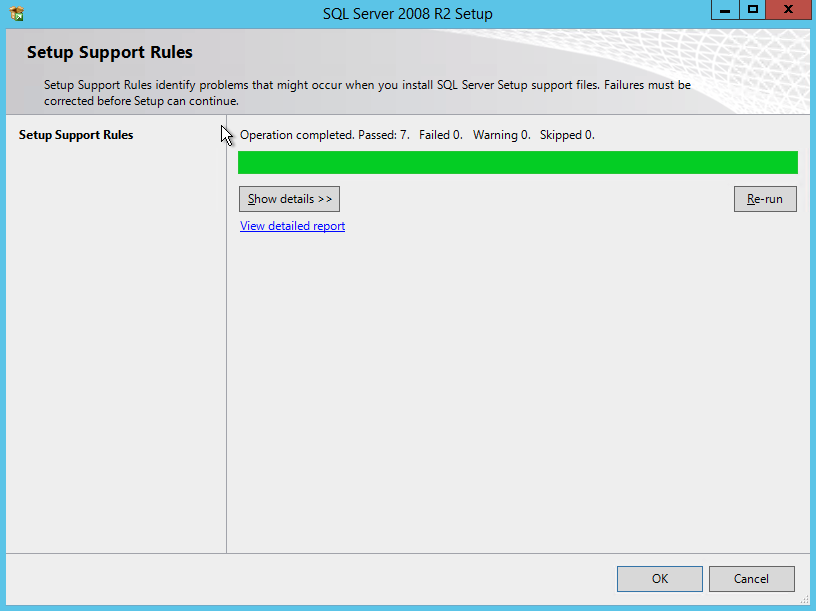
After the cluster creates, run Test-Cluster. This is required before SQL Server will install.
Test-Cluster
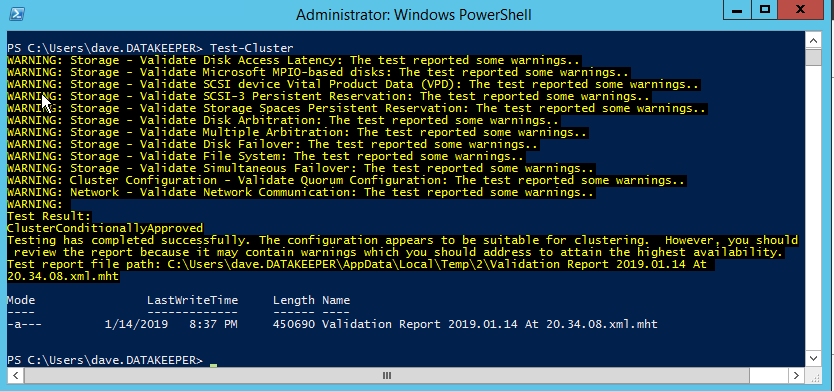
You will get warnings about Storage and Networking, but you can ignore those as they are expected in a SANless cluster in Azure. If there are any other warnings or errors you must address those before moving on.
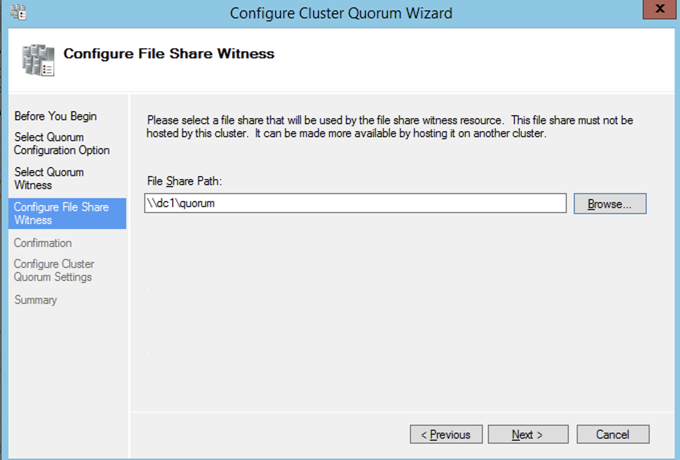
After the cluster is created you will need to add the File Share Witness. On the third server we specified as the file share witness, create a file share and give Read/Write permissions to the cluster computer object we just created above. In this case $Cluster1 will be the name of the computer object that needs Read/Write permissions at both the share and NTFS security level.
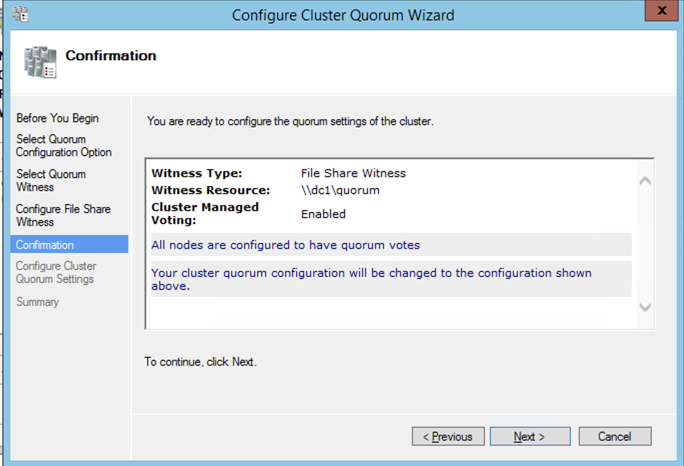
Once the share is created, you can use the Configure Cluster Quorum Wizard as shown below to configure the File Share Witness.
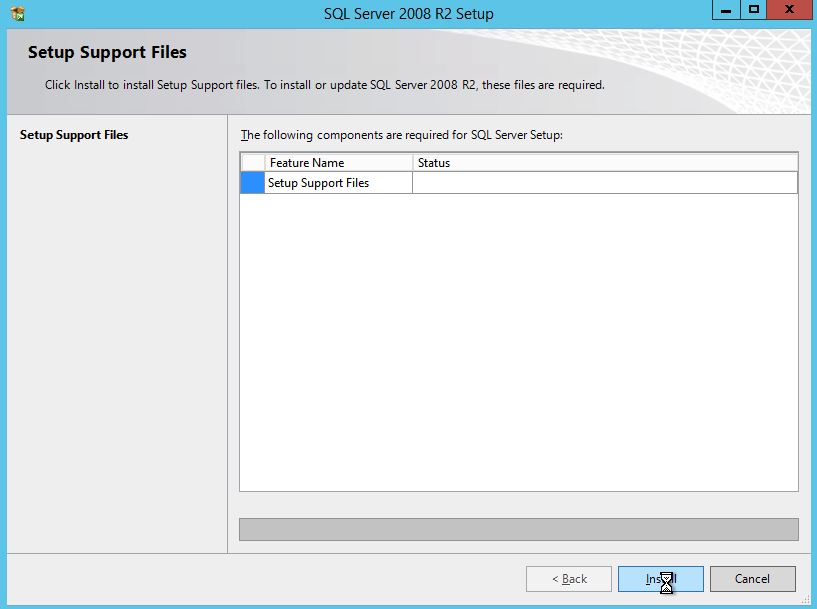
Install DataKeeper
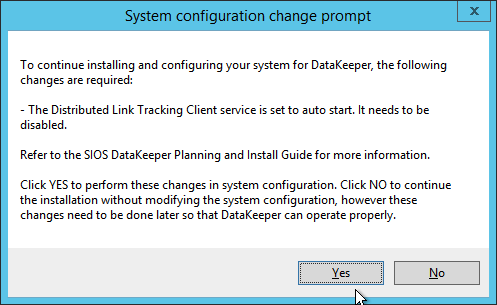
It is important to wait until the basic cluster is created before we install DataKeeper since the DataKeeper installation registers the DataKeeper Volume Resource type in failover clustering. If you jumped the gun and installed DataKeeper already that is okay. Simply run the setup again and choose Repair Installation.
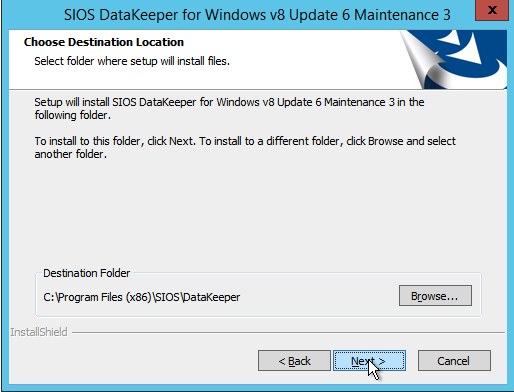
The screenshots below walk you through a basic installation. Start by running the DataKeeper Setup.
The account you specify below must be a domain account and must be part of the Local Administrators group on each of the cluster nodes.
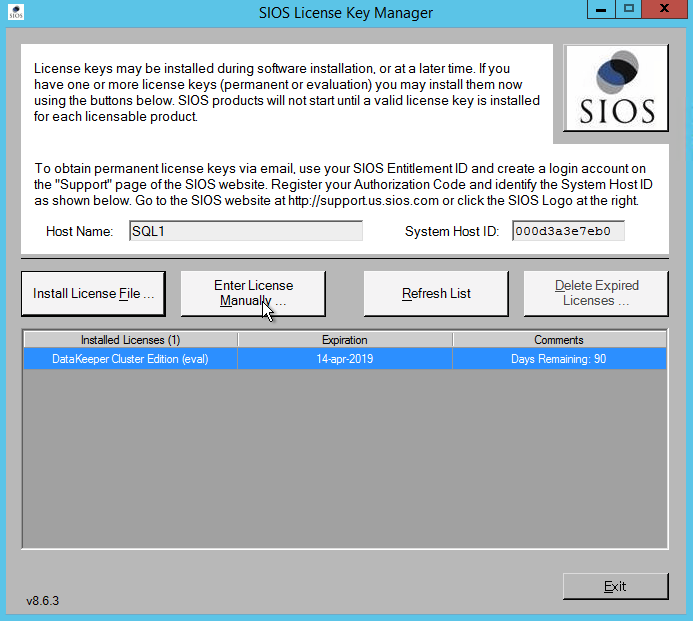
When presented with the SIOS License Key manager you can browse out to your temporary key, or if you have a permanent key you can copy the System Host ID and use that to request your permanent license. If you ever need to refresh a key the SIOS License Key Manager is a program that will be installed that you can run separately to add a new key.
Create DataKeeper Volume Resource
Once DataKeeper is installed on each node you are ready to create your first DataKeeper Volume Resource. The first step is to open the DataKeeper UI and connect to each of the cluster nodes.
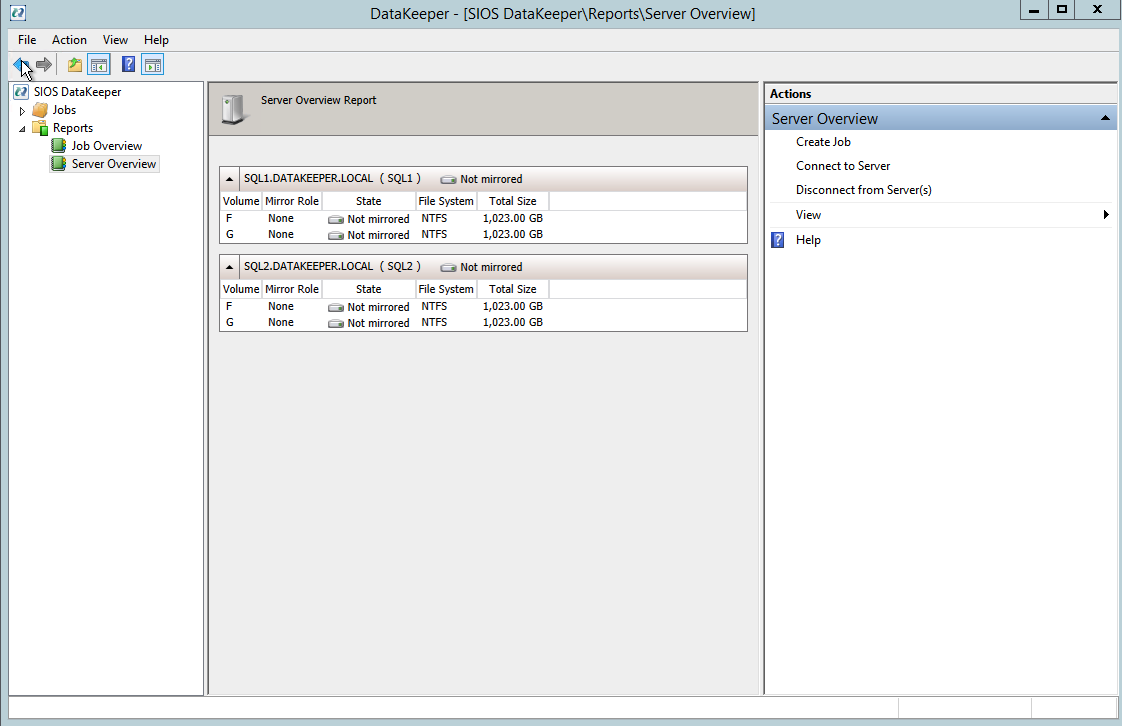
If everything is done correctly the Server Overview Report should look something like this.
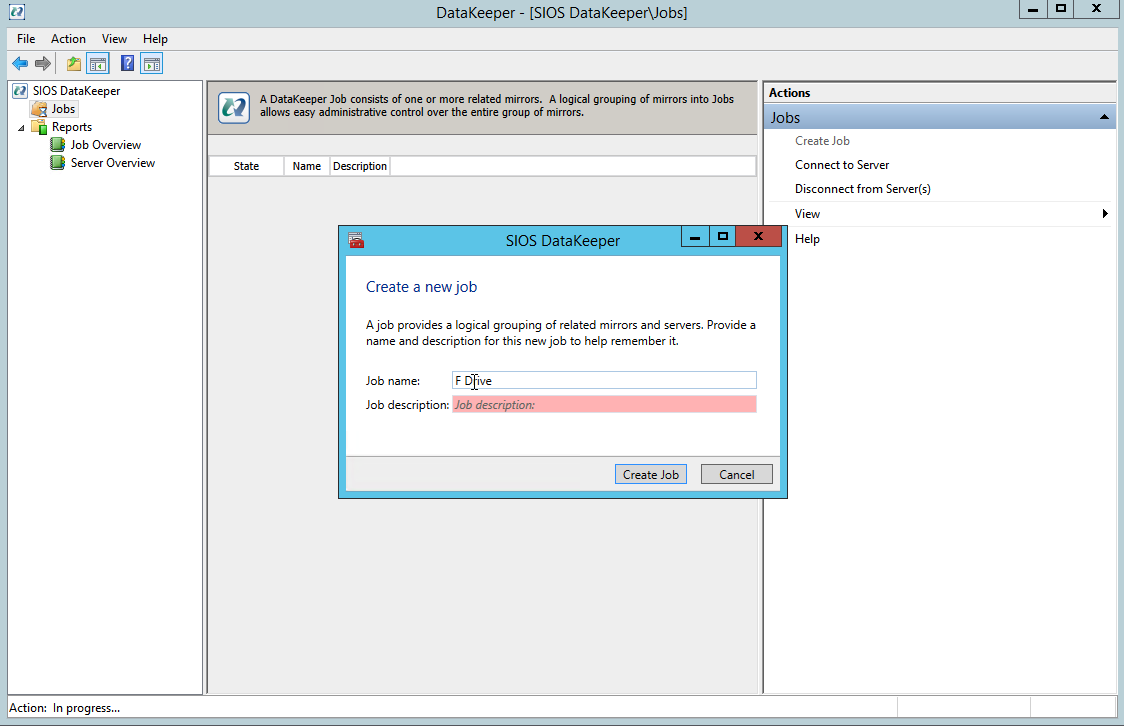
You can now create your first Job as shown below.
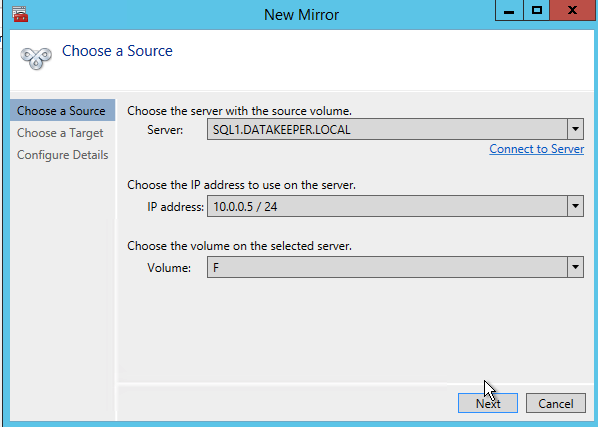
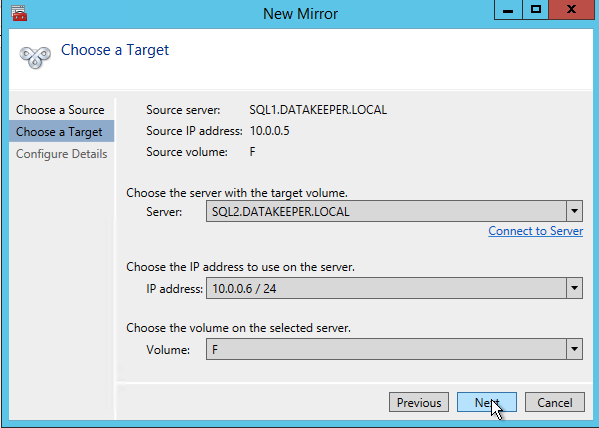
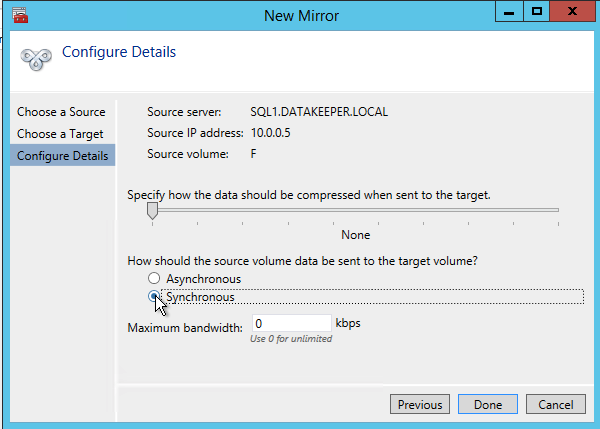
After you choose a Source and Target you are presented with the following options. For a local target in the same region the only thing you need to select is Synchronous.
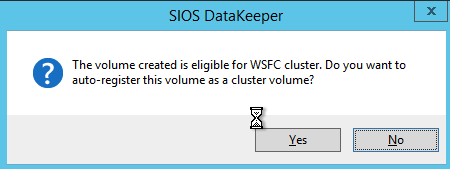
Choose Yes and auto-register this volume as a cluster resource.
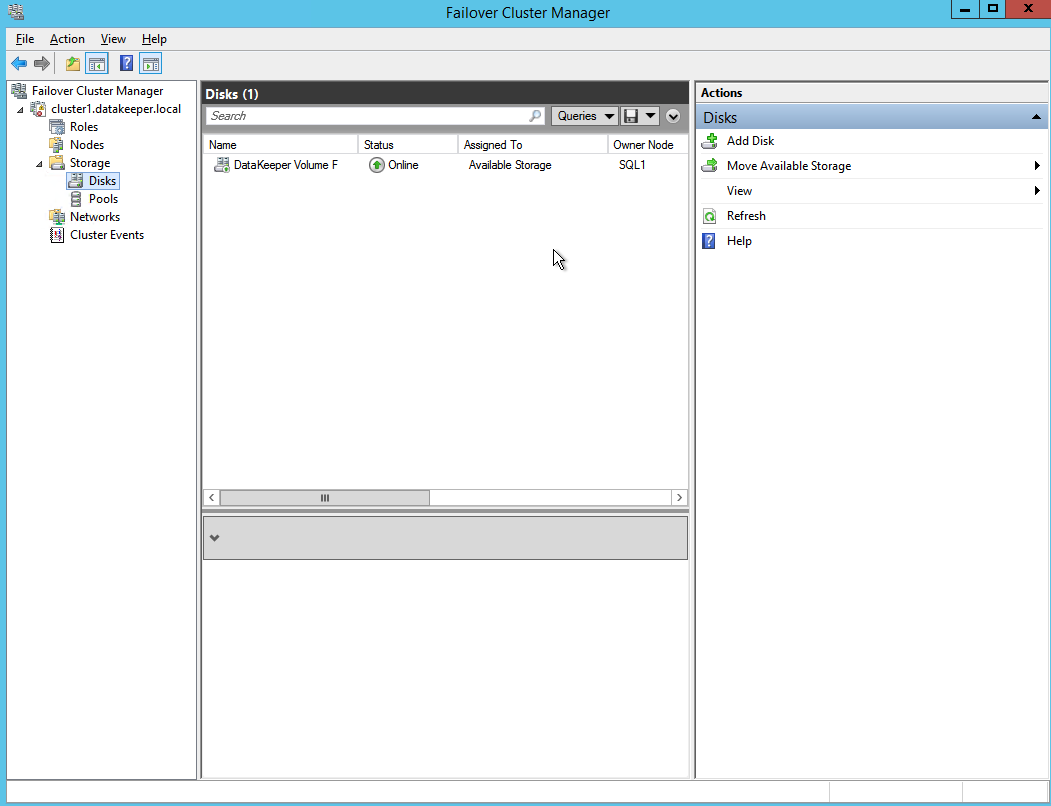
Once you complete this process open up the Failover Cluster Manager and look in Disk. You should see the DataKeeper Volume resource in Available Storage. At this point WSFC treats this as if it were a normal cluster disk resource.
Slipstream SP3 onto SQL 2008 R2 install media
SQL Server 2008 R2 is only supported on Windows Server 2012 R2 with SQL Server SP2 or later. Unfortunately, Microsoft never released a SQL Server 2008 R2 installation media that that includes SP2 or SP3. Instead, you must slipstream the service pack onto the installation media BEFORE you do the installation. If you try to do the installation with the standard SQL Server 2008 R2 media you will run into all kinds of problems. I don’t remember the exact errors you will see, but I do recall they didn’t really point to the exact problem and you will waste a lot of time trying to figure out what went wrong.
As of the date of this writing, Microsoft does not have a Windows Server 2012 R2 with SQL Server 2008 R2 offering in the Azure Marketplace, so you will be bringing your own SQL license if you want to run SQL 2008 R2 on Windows Server 2012 R2 in Azure. If they add that image later, or if you choose to use the SQL 2008 R2 on Windows Server 2008 R2 image you must first uninstall the existing standalone instance of SQL Server before moving forward.
I followed the guidance in Option 1 of this article to slipstream SP3 on onto my SQL 2008 R2 installation media. You will of course have to adjust a few things as this article references SP2 instead of SP3. Make sure you slipstream SP3 on the installation media we will use for both nodes of the cluster. Once that is done, continue to the next step.
Install SQL Server on the First Node
Using the SQL Server 2008 R2 media with SP3 slipstreamed, run setup and install the first node of the cluster as shown below.
If you use anything other than the Default instance of SQL Server you will have some additional steps not covered in this guide. The biggest difference is you must lock down the port that SQL Server uses since by default a named instance of SQL Server does NOT use 1433. Once you lock down the port you also need to specify that port instead of 1433 whenever we reference port 1433 in this guide, including the firewall setting and the Load Balancer settings.
Here make sure to specify a new IP address that is not in use. This is the same IP address we will use later when we configure the Internal Load Balancer later.
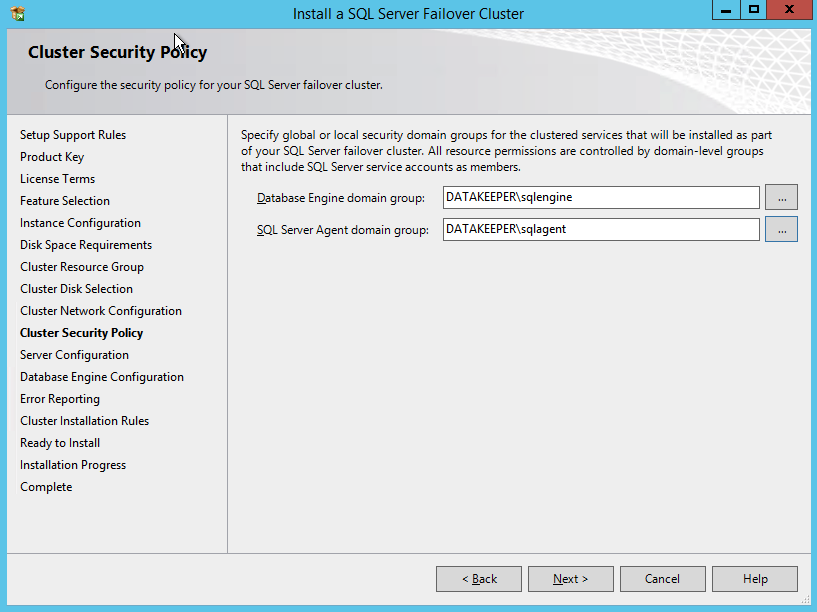
As I mentioned earlier, SQL Server 2008 R2 utilizes AD Security Groups. If you have not already created them, go ahead and create them now as show below before you continue to the next step in the SQL install
Specify the Security Groups you created earlier.
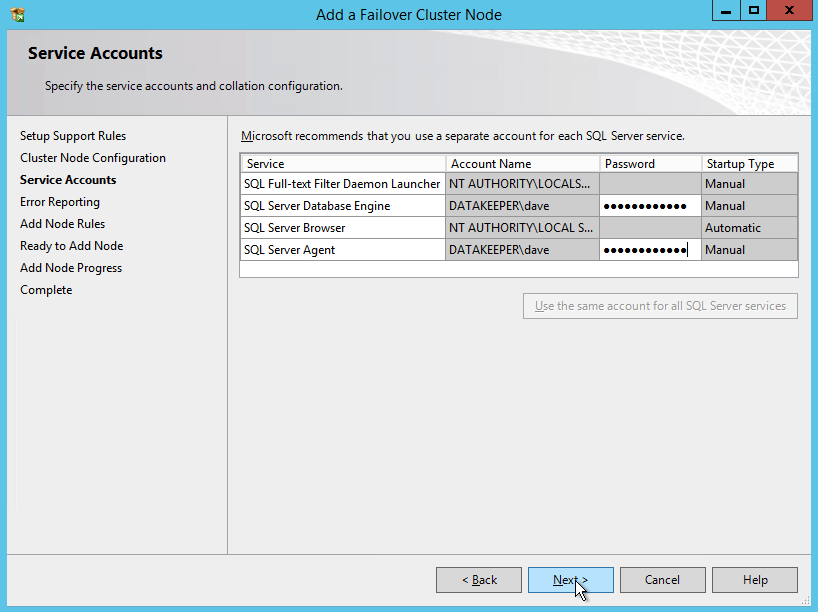
Make sure the service accounts you specify are a member of the associated Security Group.
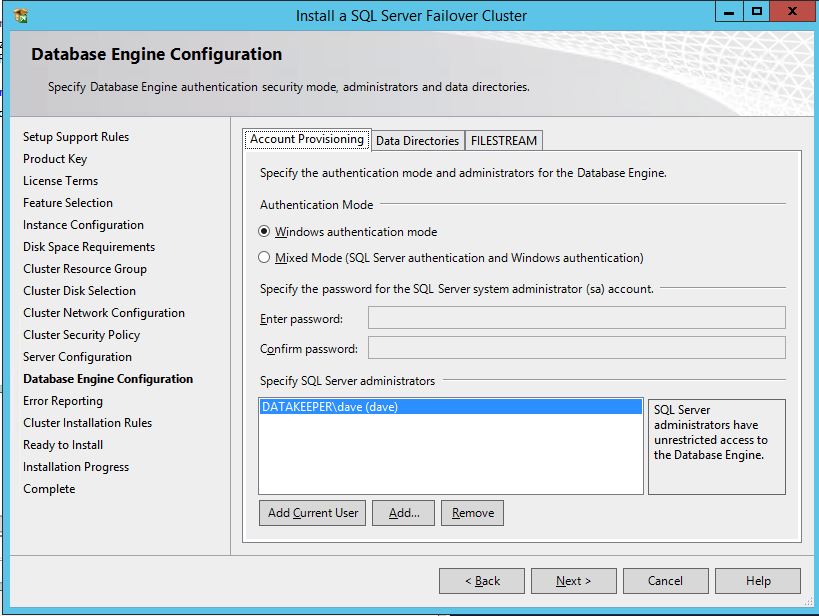
Specify your SQL Server administrators here.
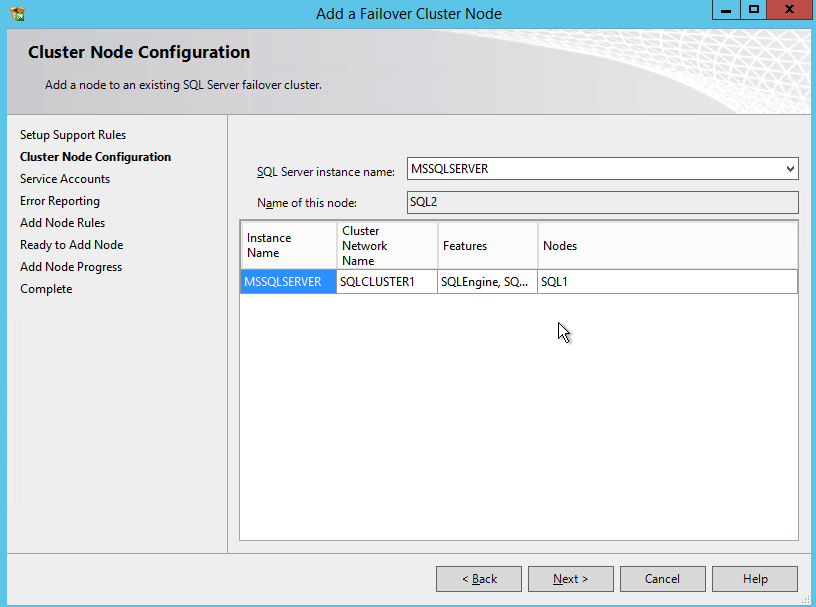
If everything goes well you are now ready to install SQL Server on the second node of the cluster.
Install SQL Server on the Second Node
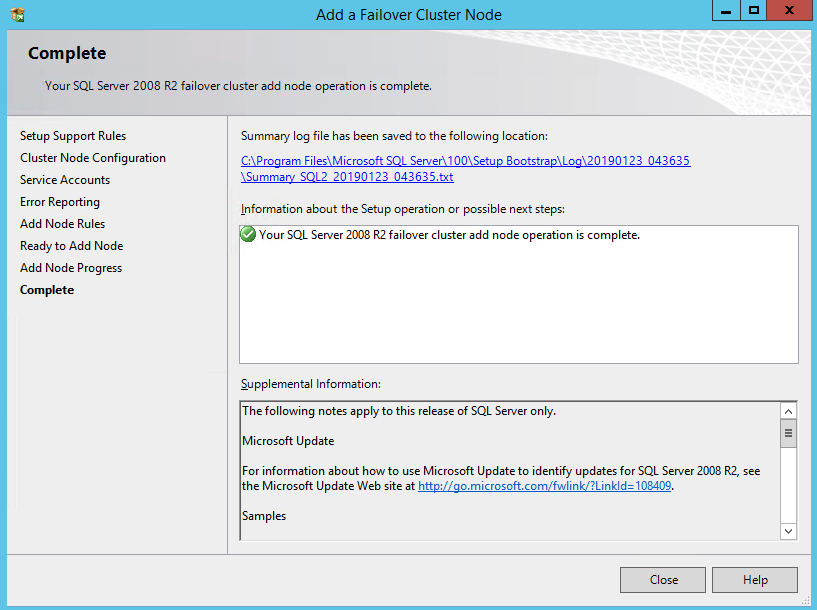
One the second node, run the SQL Server 2008 R2 with SP3 install and select Add Node to a SQL Server FCI.
Proceed with the installation as shown in the following screenshots.
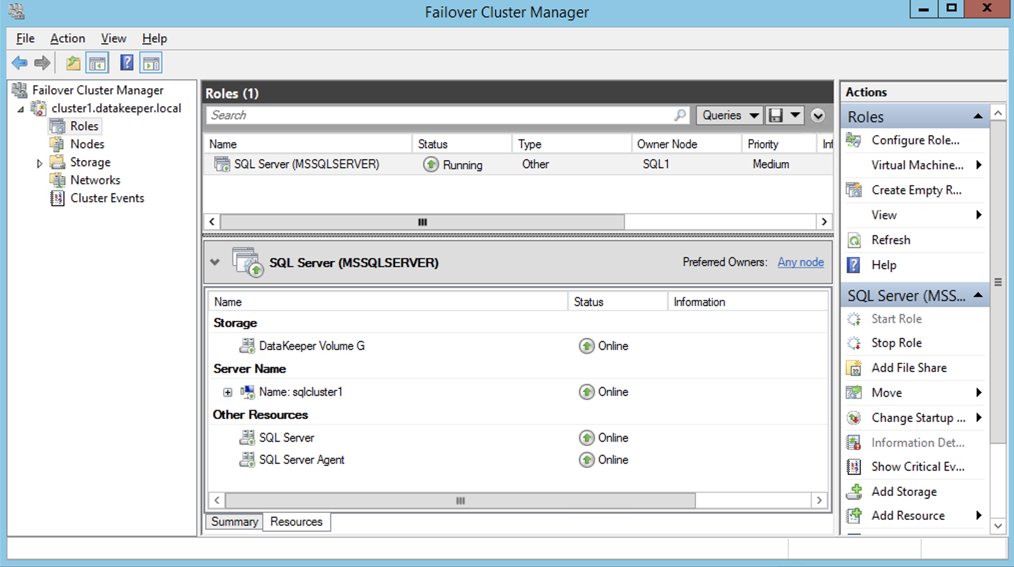
Assuming everything went well, you should now have a two node SQL Server 2008 R2 cluster configured that looks something like the following.
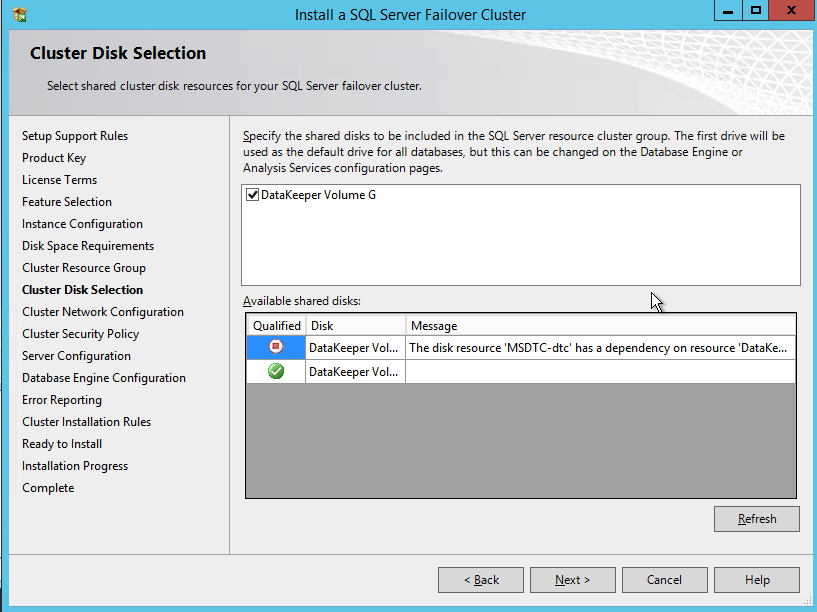
However, you probably will notice that you can only connect to the SQL Server instance from the active cluster node. The problem is that Azure does not support gratuitous ARP, so your clients cannot connect directly to the Cluster IP Address. Instead, the clients must connect to an Azure Load Balancer, which will redirect the connection to the active node. To make this work there are two steps: Create the Load Balancer and Fix the SQL Server Cluster IP to respond to the Load Balancer Probe and use a 255.255.255.255 Subnet mask. Those steps are described below.
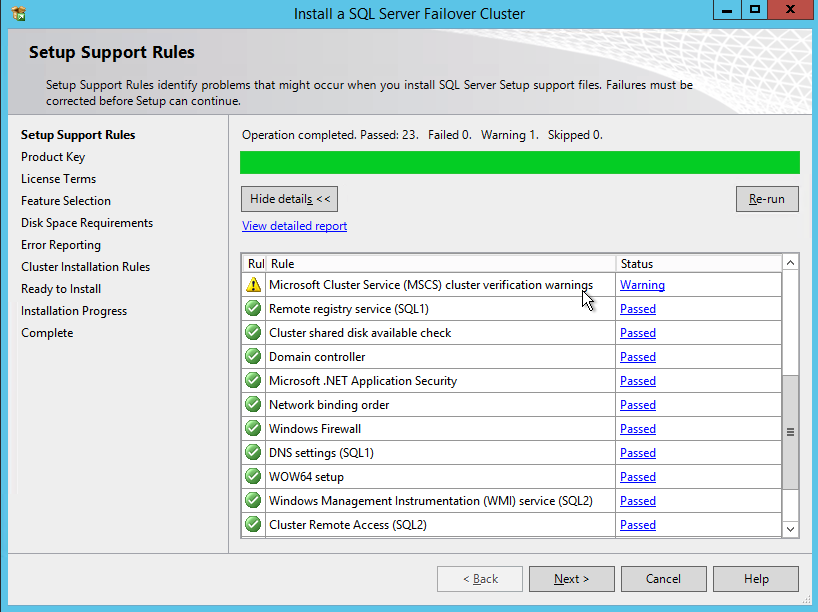
Before you continue, run cluster validation one more time. The Cluster Validation report should return just the same network and storage warnings that it did the first time you ran it. Assuming there are no new errors or warnings, your cluster is configured correctly.
Edit sqlserv.exe Config File
include the below lines in the sqlservr.exe.config file. This forces SQL Server to use the right CLR integration.
The file, by default, will not exist and may be created. If this file already exists for your installation, the <supportedRuntime version=”v2.0.50727″/> line simply needs to be placed with the <startup>…</startup> sub-section of the <configuration>…</configuration> section.
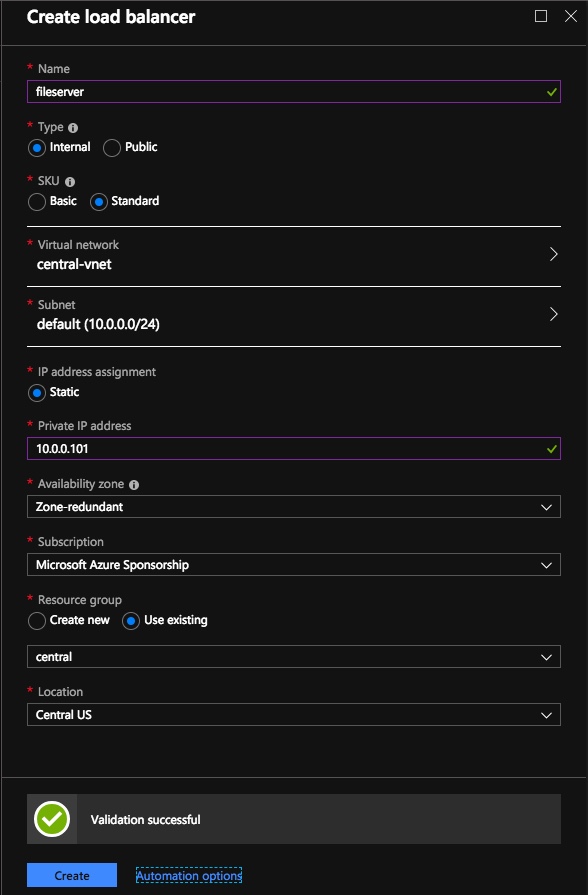
Create the Azure Load Balancer
I’m going to assume your clients can communicate directly to the internal IP address of the SQL cluster so we will create an Internal Load Balancer (ILB) in this guide. If you need to expose your SQL Instance on the public internet you can use a Public Load Balancer instead.
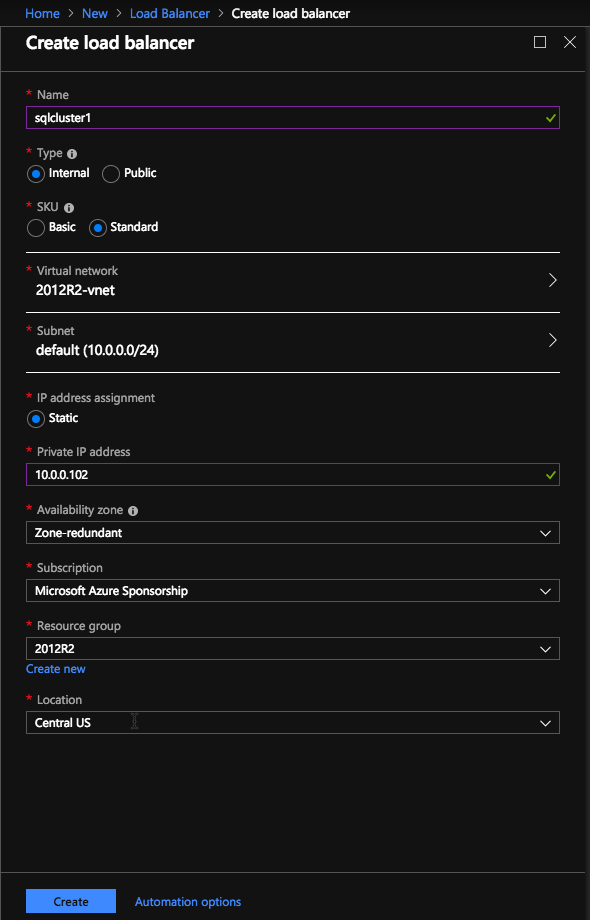
In the Azure portal create a new Load Balancer following the screenshots as shown below. The Azure portal UI changes rapidly, but these screenshots should give you enough information to do what you need to do. I will call out important settings as we go along.
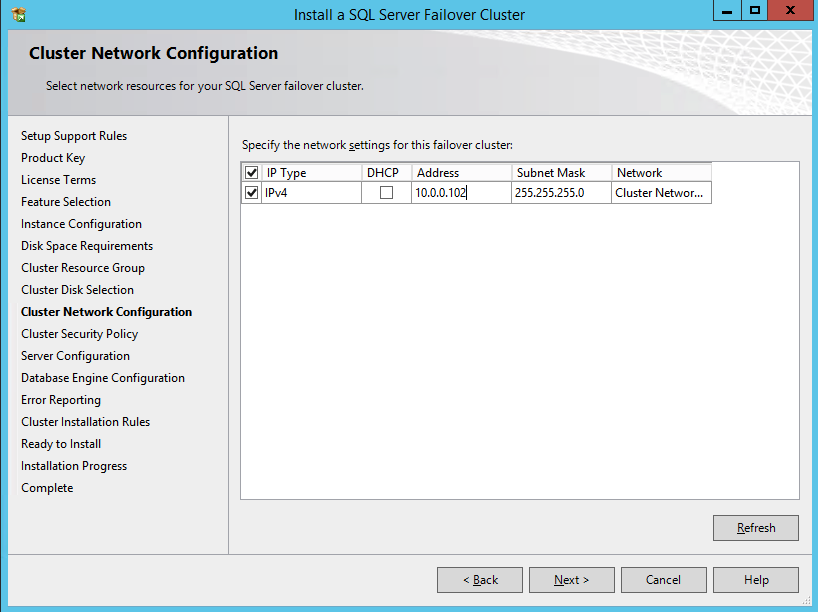
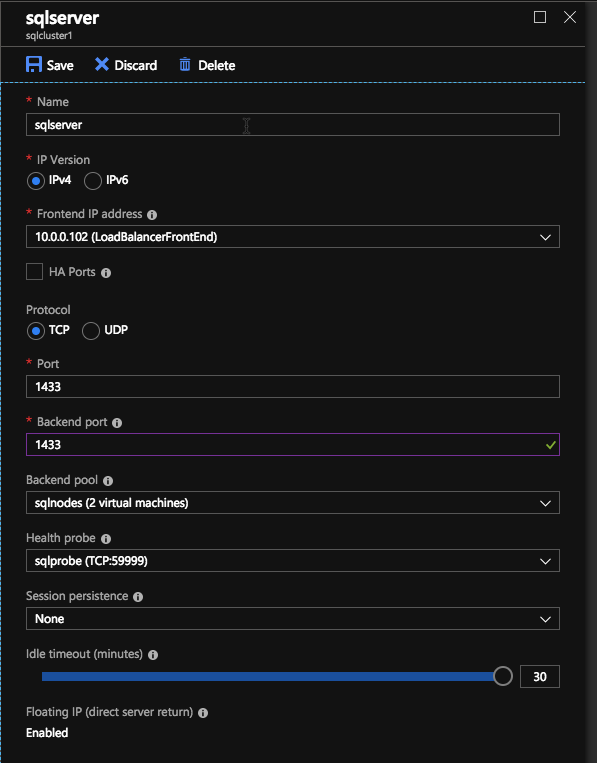
Here we create the ILB. The important thing to note on this screen is you must select “Static IP address assignment” and specify the same IP address that we used during the SQL Cluster installation.
Since I used Availability Zones I see Zone Redundant as an option. If you used Availability Sets your experience will be slightly different.
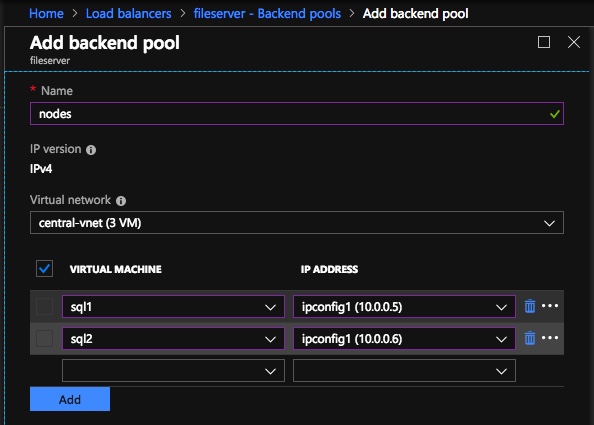
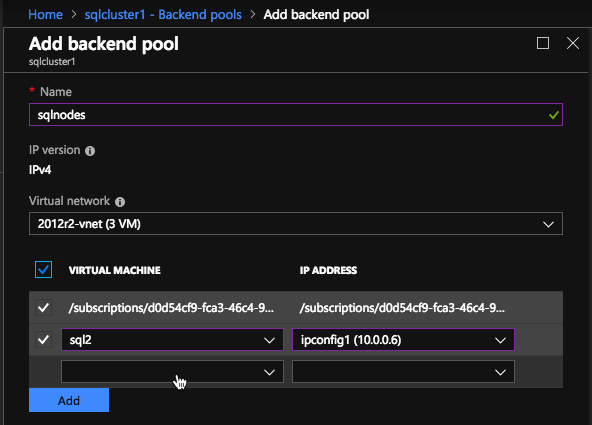
In the Backend pool be sure to select the two SQL Server instances. You DO NOT want to add your File Share Witness in the pool.
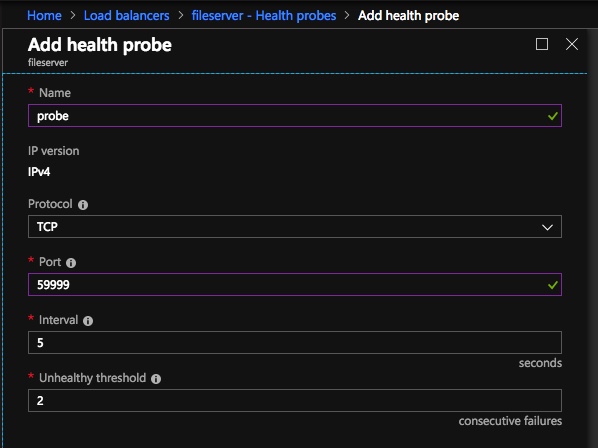
Here we configure the Health Probe. Most Azure documentation has us using port 59999, so we will stick with that port for our configuration.
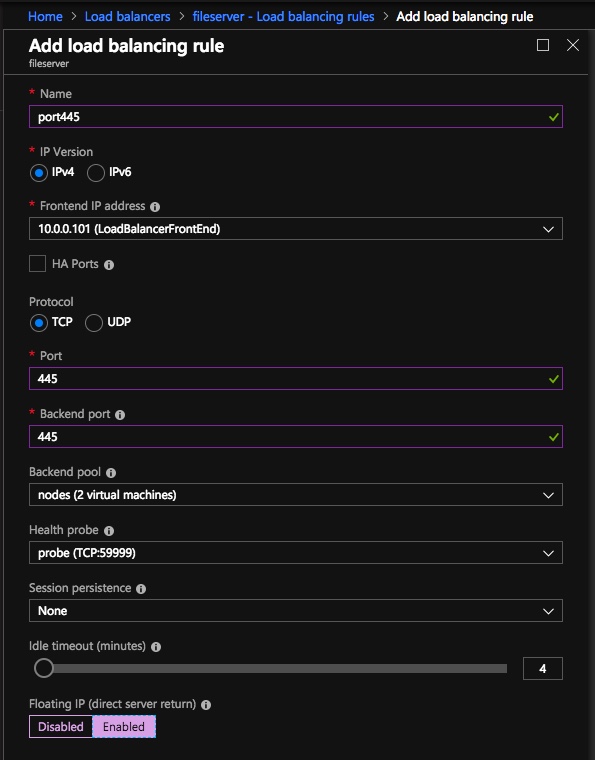
Here we will add a load balancing rule. In our case we want to redirect all SQL Server traffic to TCP port 1433 of the active node. It is also important that you select Floating IP (Direct Server Return) as Enabled.
Run Powershell Script to Update SQL Client Access Point
Now we must run a Powershell script on one of the cluster nodes to allow the Load Balancer Probe to detect which node is active. The script also sets the Subnet Mask of the SQL Cluster IP Address to 255.255.255.255.255 so that it avoids IP address conflicts with the Load Balancer we just created.
# Define variables
$ClusterNetworkName = “”
# the cluster network name (Use Get-ClusterNetwork on Windows Server 2012 of higher to find the name)
$IPResourceName = “”
# the IP Address resource name
$ILBIP = “”
# the IP Address of the Internal Load Balancer (ILB) and SQL Cluster
Import-Module FailoverClusters
# If you are using Windows Server 2012 or higher:
Get-ClusterResource $IPResourceName | Set-ClusterParameter -Multiple @{Address=$ILBIP;ProbePort=59999;SubnetMask="255.255.255.255";Network=$ClusterNetworkName;EnableDhcp=0}
# If you are using Windows Server 2008 R2 use this:
#cluster res $IPResourceName /priv enabledhcp=0 address=$ILBIP probeport=59999 subnetmask=255.255.255.255
This is what the output will look like if run correctly.
You probably notice that the end of that script has a commented line of code to use if you are running on Windows Server 2008 R2. If you are running Windows Server 2008 R2 make sure you run the code specific for Windows Server 2008 R2 at a Command prompt, it is not Powershell.
Next Steps
If you get to this point and you still cannot connect to the cluster remotely you wouldn’t be the first person. There are a lot of things that can go wrong in terms of security, load balancer, SQL ports, etc. I wrote this guide to help troubleshoot connection issues.
In fact, in this very installation I ran into some strange issues in terms of my SQL Server TCP/IP Properties in SQL Server Configuration Manager. When I looked at the properties I did not see the SQL Server Cluster IP address as one of the addresses it was listening on, so I had to add it manually. I’m not sure if that was an anomaly, but it certainly was an issue I had to resolve before I could connect to the cluster from a remote client.
As I mentioned earlier, one other improvement you can make to this installation is to use a DataKeeper Non-Mirrored Volume Resource for TempDB. If you set that up please be aware of the following two configuration issues people commonly run into.
The first issue is if you move tempdb to a folder on the 1st node, you must be sure to create the exact same folder structure on the second node. If you don’t do that when you try to failover SQL Server will fail to come online since it can’t create TempDB
The second issue occurs anytime you add another DataKeeper Volume Resource to a SQL Cluster after the cluster is created. You must go into the properties of the SQL Server cluster resource and make it dependent on the new DataKeeper Volume resource you added. This is true for the TempDB volume and any other volumes you may decide to add after the cluster is created.
If you have any questions about this configuration or any other cluster configurations please feel free to reach out to me on Twitter @DaveBerm.
My previous blog posts, Azure Outage Post-Mortem – Part 1 and Azure Outage Post-Mortem Part 2,made some assumptions based upon limited information coming from blog posts and twitter. I just attended a session at Ignite which gave a little more clarity as to what actually happened. Sometime tomorrow you should be able to view the session for yourself.
The official Root Cause Analysis they said will be published soon, but in the meantime here are some tidbits of information gleaned from the session.
The outage was NOT caused by a lightning strike as previously reported. Instead, due to the nature of the storm there were electrical storm sags and swells, which locked out a chiller plant in the 1st datacenter. During this first outage they were able to recover the chiller quickly with no noticeable impact. Shortly thereafter, there was a second outage at a second datacenter which was not recovered properly, which began an unfortunate series of events.
During this 2nd outage, Microsoft states that “Engineers didn’t triage alerts correctly – chiller plant recovery was not prioritized”. There were numerous alerts being triggered at this time, and unfortunately the chiller being offline did not receive the priority it should have. The RCA as to why that happened is still being investigated.
Microsoft states that of course redundant chiller systems are in place. However, the cooling systems were not set to automatically failover. Recently installed new equipment had not been fully tested, so it was set to manual mode until testing had been completed.
After 45 minutes the ambient cooling failed, hardware shutdown, air handlers shut down because they thought there was a fire, and staff had been evacuated due to the false fire alarm. During this time temperature in the data center was increasing and some hardware was not shut down properly, causing damage to some storage and networking.
After manually resetting the chillers and opening the air handlers the temperature began to return to normal. It took about 3 hours and 29 minutes before they had a complete picture of the status of the datacenter.
The biggest issue was there was damage to storage. Microsoft’s primary concern is data protection, so short of the enter datacenter sinking into a sinkhole or a meteor strike taking out the datacenter, Microsoft will work to recover data to ensure no data loss. This of course took some time, which extend the overall length of the outage. The good news is that no customer data was lost, the bad news is that it seemed like it took 24-48 hours for things to return to normal, based upon what I read on Twitter from customers complaining about the prolonged outage.
Everyone expected that this outage would impact customers hosted in the South Central Region, but what they did not expect was that the outage would have an impact outside of that region. In the session, Microsoft discusses some of the extended reach of the outage.
Azure Service Manager (ASM) – This controls Azure “Classic” resources, AKA, pre-ARM resources. Anyone relying on ASM could have been impacted. It wasn’t clear to me why this happened, but it appears that South Central Region hosts some important components of that service which became unavailable.
Visual Studio Team Service (VSTS) – Again, it appears that many resources that support this service are hosted in the South Central Region. This outage is described in great detail by Buck Hodges (@tfsbuck), Director of Engineering, Azure DevOps this blog post.
Azure Active Directory (AAD) – When the South Central region failed, AAD did what it was designed to due and started directing authentication requests to other regions. As the East Coast started to wake up and online, authentication traffic started picking up. Now normally AAD would handle this increase in traffic through autoscaling, but the autoscaling has a dependency on ASM, which of course was offline. Without the ability to autoscale, AAD was not able to handle the increase in authentication requests. Exasperating the situation was a bug in Office clients which made them have very aggressive retry logic, and no backoff logic. This additional authentication traffic eventually brought AAD to its knees.
They ran out of time to discuss this further during the Ignite session, but one feature that they will be introducing will be giving users the ability to failover Storage Accounts manually in the future. So in the case where recovery time objective (RTO) is more important than (RPO) the user will have the ability to recover their asynchronously replicated geo-redundant storage in an alternate data center should Microsoft experience another extended outage in the future.
Until that time, you will have to rely on other replication solutions such as SIOS DataKeeperAzure Site Recovery, or application specific replication solutions which give you the ability to replicate data across regions and put the ability to enact your disaster recovery plan in your control.
My previous blog post says that Cloud-to-Cloud or Hybrid-Cloud would give you the most isolation from just about any issue a CSP could encounter. However, in this particular failure had Availability Zones been available in the South Central region most of the downtime caused by this natural disaster could have been avoided. Microsoft published a Preliminary RCA of the September 4th South Central Outage.
The most important part of that whole summary is as follows…
“Despite onsite redundancies, there are scenarios in which a datacenter cooling failure can impact customer workloads in the affected datacenter.”
What does that mean to you? If your applications all run in the same datacenter you are susceptible to the same type of outage in the future. In Microsoft’s defense, this really shouldn’t be news to you as this has always been true whether you run in Azure, AWS, Google or even your own datacenter. Failure to plan ahead with data replication to a different datacenter and a plan in place to quickly recover your applications in those datacenters in the event of a disaster is simply a lack of planning on your part.
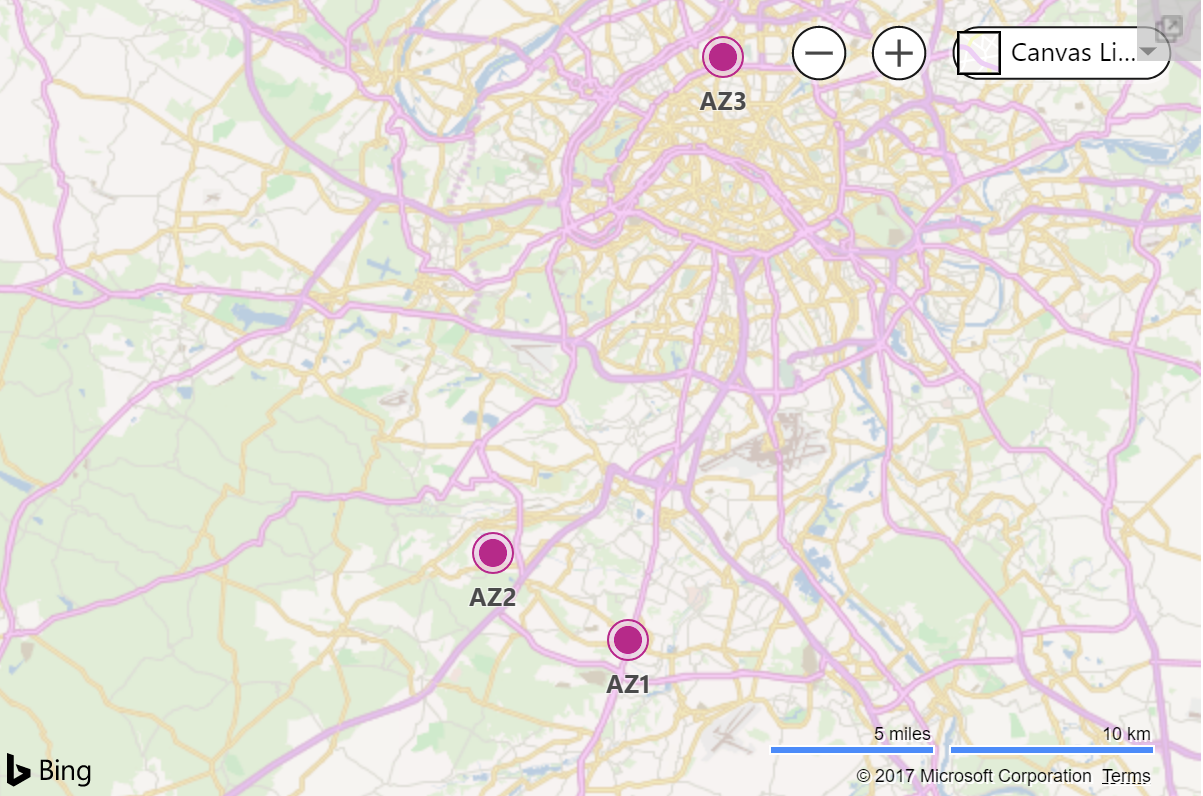
While Microsoft doesn’t publish exact Availability Zone locations, if you believe this map published here you could guess that they are probably anywhere from a 2-10 miles apart from each other.
In all but the most extreme cases, replicating data across Availability Zones should be sufficient for data protection. Some applications such as SQL Server have built in replication technology, but for a broad range of applications, operating systems and data types you will want to investigate block level replication SANless cluster solutions. SANless cluster solutions have traditionally been used for multisite clusters, but the same technology can also be used in the cloud across Availability Zones, Regions, or Hybrid-Cloud for high availability and disaster recovery.
Implementing a SANless cluster that spans Availability Zones, whether it is Azure, AWS or Google, is a pretty simple process given the right tools. Here are a few resources to help get you started.
If you are in Azure you may also want to consider Azure Site Recovery (ASR). ASR lets you replicate the entire VM from one Azure region to another region. ASR will replicate your VMs in real-time and allow you to do a non-disruptive DR test whenever you like. It supports most versions of Windows and Linux and is relatively easy to set up.
You can also create replication jobs that have “Multi-VM Consistency”, meaning that servers that must be recovered from the exact same point in time can be put together in this consistency group and they will have the exact same recovery point. What this means is if you wanted to build a SANless cluster with DataKeeper in a single region for high availability you have two options for DR. One is you could extend your SANless cluster to a node in a different region, or else you could simply use ASR to replicate both nodes in a consistency group.
The trade off with ASR is that the RPO and RTO is not as good as you will get with a SANless multi-site cluster, but it is easy to configure and works with just about any application. Just be careful, if your application exceeds 10 MBps in disk write activity on a regular basis ASR will not be able to keep up. Also, clusters based on Storage Spaces Direct cannot be replicated with ASR and in general lack a good DR strategy when used in Azure.
For a while after Managed Disks were released ASR did not fully support them until about a year later. Full support for Managed Disks was a big hurdle for many people looking to use ASR. Fortunately since about February of 2018 ASR fully supports Managed Disks. However, there is another problem that was just introduced.
With the introduction of Availability Zones ASR is once again caught behind the times as they currently don’t support VMs that have been deployed in Availability Zones.
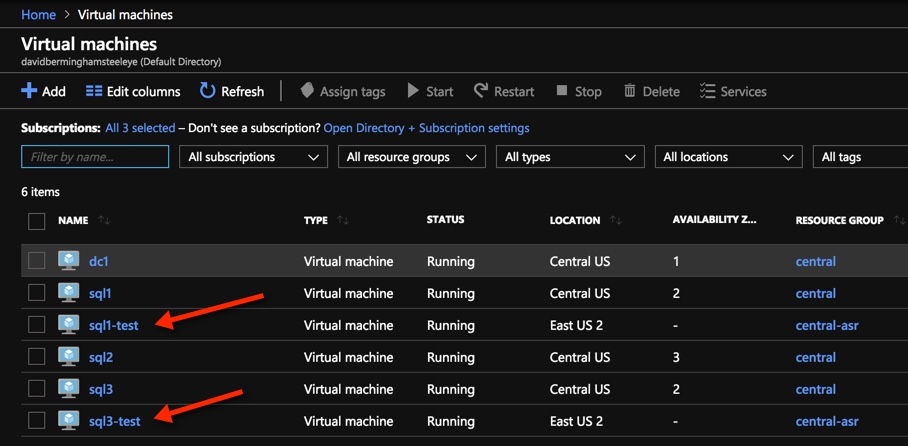
I went ahead and tried it anyway. I seemed to be able to configure replication and was able to do a test failover.
I used ASR to replicate SQL1 and SQL3 from Central to East US 2 and did a test failover. Other than not placing the VMs in AZs in East US 2 it seems to work.
I’m hoping to find out more about this limitation at the Ignite conference. I don’t think this limitation is as critical as the Managed Disk limitation was, just because Availability Zones aren’t widely available yet. So hopefully ASR will pick up support for Availability Zones as other regions light up Availability Zones and they are more widely adopted.
In this post we will detail the specific steps required to deploy a 2-node File Server Failover Cluster that spans the new Availability Zones a single region of Azure. I will assume you are familiar with basic Azure concepts as well as basic Failover Cluster concepts and will focus this article on what is unique about deploying a File Server Failover Cluster in Azure across Availability Zones. If your Azure region doesn’t support Availability Zones yet you will have to use Fault Domains instead as described in an earlier post.
With DataKeeper Cluster Edition you are able to take the locally attached Managed Disks, whether it is Premium or Standard Disks, and replicate those disks either synchronously, asynchronously or a mix or both, between two or more cluster nodes. In addition, a DataKeeper Volume resource is registered in Windows Server Failover Clustering which takes the place of a Physical Disk resource. Instead of controlling SCSI-3 reservations like a Physical Disk Resource, the DataKeeper Volume controls the mirror direction, ensuring the active node is always the source of the mirror. As far as Failover Clustering is concerned, it looks, feels and smells like a Physical Disk and is used the same way Physical Disk Resource would be used.
Pre-requisites
You have used the Azure Portal before and are comfortable deploying virtual machines in Azure IaaS.
Deploying a File Server Failover Cluster Instance using the Azure Portal
To build a 2-node File Server Failover Cluster Instance in Azure, we are going to assume you have a basic Virtual Network based on Azure Resource Manager and you have at least one virtual machine up and running and configured as a Domain Controller. Once you have a Virtual Network and a Domain configured, you are going to provision two new virtual machines which will act as the two nodes in our cluster.
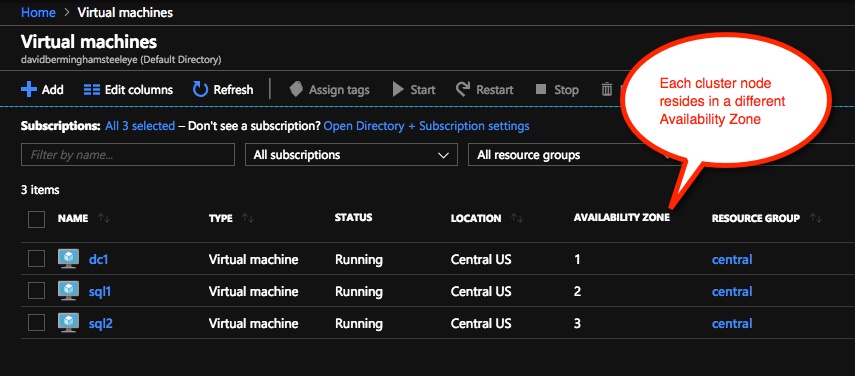
Our environment will look like this:
DC1 – Our Domain Controller and File Share Witness SQL1 and SQL2 – The two nodes of our File Server Cluster. Don’t let the names confuse you, we are building a File Server Cluster in this guide. In my next post I will demonstrate a SQL Server cluster configuration.
Provisioning the two cluster nodes
Using the Azure Portal, we will provision both SQL1 and SQL2 exactly the same way. There are numerous options to choose from including instance size, storage options, etc. This guide is not meant to be an exhaustive guide to deploying Servers in Azure as there are some really good resources out there and more published every day. However, there are a few key things to keep in mind when creating your instances, especially in a clustered environment.
Availability Zones – It is important that both SQL1, SQL2 reside in different Availability Zones. For the sake of this guide we will assume you are using Windows 2016 and will use a Cloud Witness for the Cluster Quorum. If you use Windows 2012 R2 or Windows Server 2008 R2 instead of Windows 2016 you will instead need to configure a File Share Witness in the 3rd Availability Zone as Cloud Witness was not introduced until Windows Server 2016.
By putting the cluster nodes in different Availability Zones we are ensuring that each cluster node resides in a different Azure datacenter in the same region. Leveraging Availability Zones rather than the older Fault Domains isolates you from the types of outages that occured just a few weeks ago that brought down the entire South Central region for multiple days.
Be sure to add each cluster node to a different Availability Zone. If you leverage a File Share Witness it should reside in the 3rd Availability Zone.
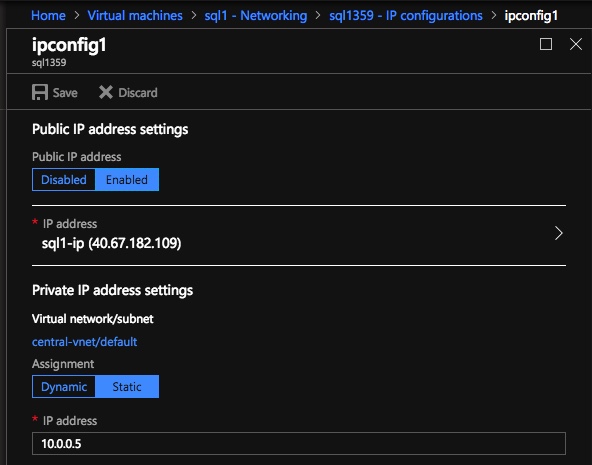
Static IP Address
Once each VM is provisioned, you will want to go into the setting and change the settings so that the IP address is Static. We do not want the IP address of our cluster nodes to change.
Make sure each cluster node uses a static IP
Storage
As far as Storage is concerned, you will want to consult Performance best practices for SQL Server in Azure Virtual Machines. In any case, you will minimally need to add at least one additional Managed Disk to each of your cluster nodes. DataKeeper can use Basic Disk, Premium Storage or even multiple disks striped together in a local Storage Space. If you do want to use a local Storage Space just be aware that you should create the Storage Space BEFORE you do any cluster configuration due to a known issue with Failover Clustering and local Storage Spaces. All disks should be formatted NTFS.
Create the Cluster
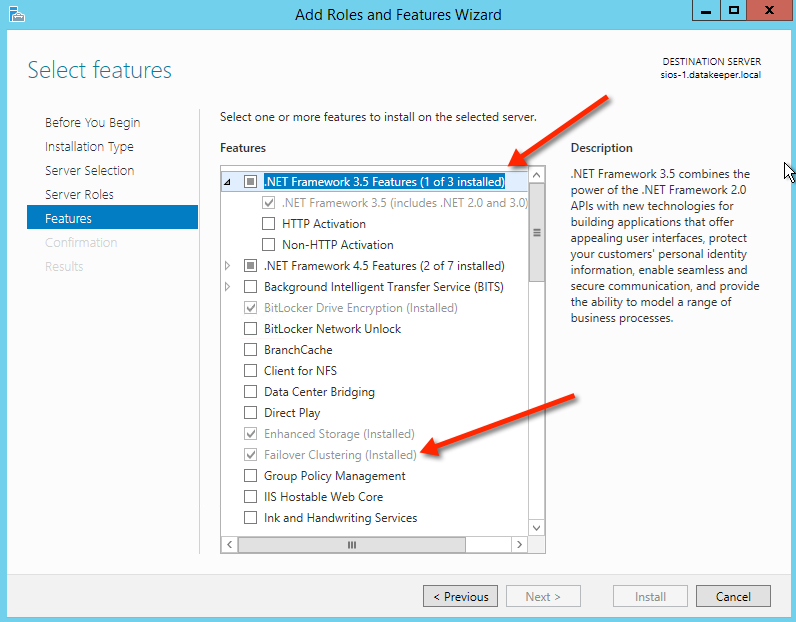
Assuming both cluster nodes (SQL1 and SQL2) have been provisioned as described above and added to your existing domain, we are ready to create the cluster. Before we create the cluster, there are a few Features that need to be enabled. These features are .Net Framework 3.5 and Failover Clustering. These features need to be enabled on both cluster nodes. You will also need to enable the FIle Server Role.
Enable both .Net Framework 3.5 and Failover Clustering features and the File Server on both cluster nodes
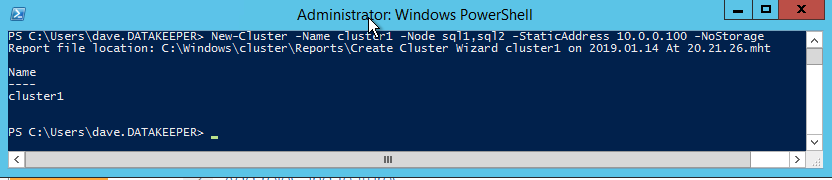
Once that role and those features have been enabled, you are ready to build your cluster. Most of the steps I’m about to show you can be performed both via PowerShell and the GUI. However, I’m going to recommend that for this very first step you use PowerShell to create your cluster. If you choose to use the Failover Cluster Manager GUI to create the cluster you will find that you wind up with the cluster being issued a duplicate IP address.
Without going into great detail, what you will find is that Azure VMs have to use DHCP. By specifying a “Static IP” when we create the VM in the Azure portal all we did was create sort of a DHCP reservation. It is not exactly a DHCP reservation because a true DHCP reservation would remove that IP address from the DHCP pool. Instead, this specifying a Static IP in the Azure portal simply means that if that IP address is still available when the VM requests it, Azure will issue that IP to it. However, if your VM is offline and another host comes online in that same subnet it very well could be issued that same IP address.
There is another strange side effect to the way Azure has implemented DHCP. When creating a cluster with the Windows Server Failover Cluster GUI, there is not option to specify a cluster IP address. Instead it relies on DHCP to obtain an address. The strange thing is, DHCP will issue a duplicate IP address, usually the same IP address as the host requesting a new IP address. The cluster install will complete, but you may have some strange errors and you may need to run the Windows Server Failover Cluster GUI from a different node in order to get it to run. Once you get it to run you will need to change the core cluster IP address to an address that is not currently in use on the network.
You can avoid that whole mess by simply creating the cluster via Powershell and specifying the cluster IP address as part of the PowerShell command to create the cluster.
You can create the cluster using the New-Cluster command as follows:
After the cluster creation completes, you will also want to run the cluster validation by running the following command. You should expect to see some warnings about storage and network, but that is expected in Azure and you can ignore those warnings. If any errors are reported you will need to address those before you move on.
Test-Cluster
Create a Quorum Witness
if you are running Windows 2016 or 2019 you will need to create a Cloud Witness for the cluster quorum. If you are running Windows Server 2012 R2 or 2008 R2 you will need to create a File Share Witness. The detailed instruction on witness creation can be found here.
Install DataKeeper
After the cluster is created it is time to install DataKeeper. It is important to install DataKeeper after the initial cluster is created so the custom cluster resource type can be registered with the cluster. If you installed DataKeeper before the cluster is created you will simply need to run the install again and do a repair installation.
Install DataKeeper after the cluster is created
During the installation you can take all of the default options. The service account you use must be a domain account and be in the local administrators group on each node in the cluster.
The service account must be a domain account that is in the Local Admins group on each node
Once DataKeeper is installed and licensed on each node you will need to reboot the servers.
Create the DataKeeper Volume Resource
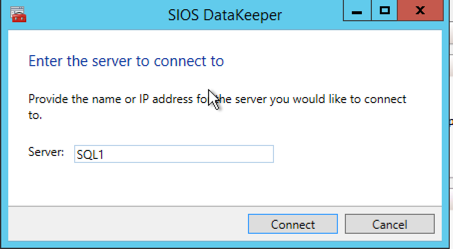
To create the DataKeeper Volume Resource you will need to start the DataKeeper UI and connect to both of the servers. Connect to SQL1
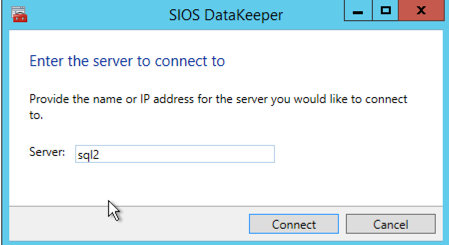
Connect to SQL2
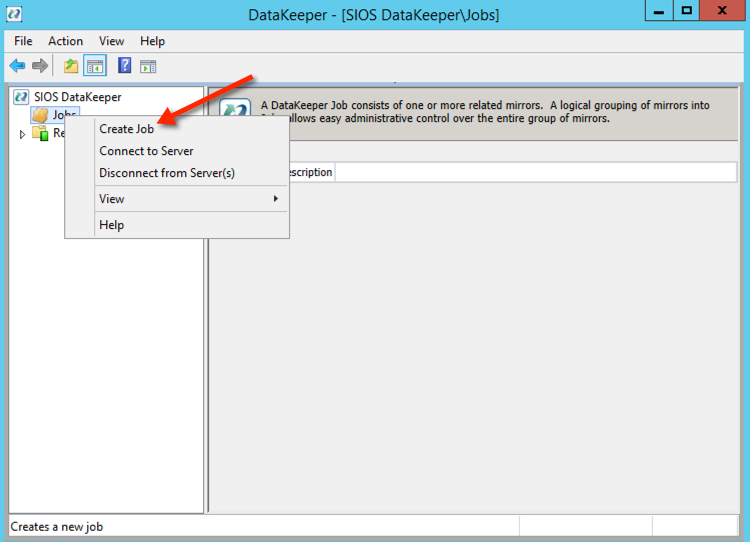
Once you are connected to each server, you are ready to create your DataKeeper Volume. Right click on Jobs and choose “Create Job”
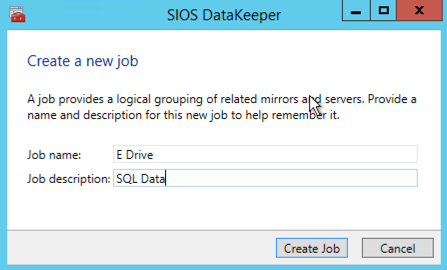
Give the Job a name and description.
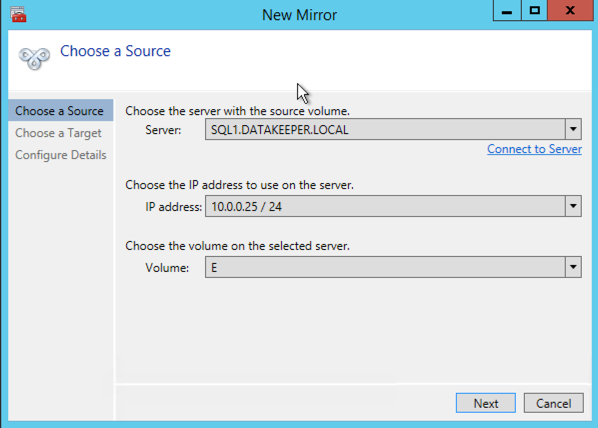
Choose your source server, IP and volume. The IP address is whether the replication traffic will travel.
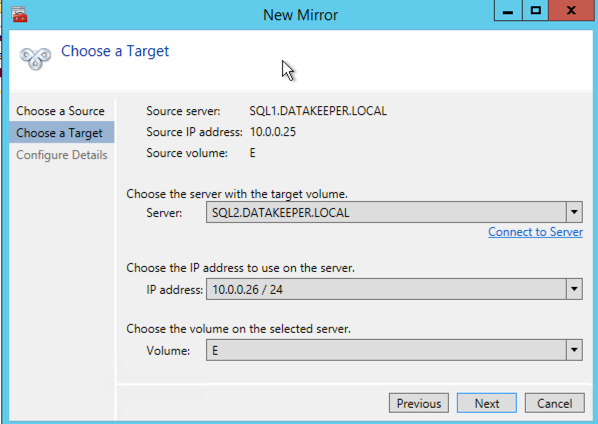
Choose your target server.
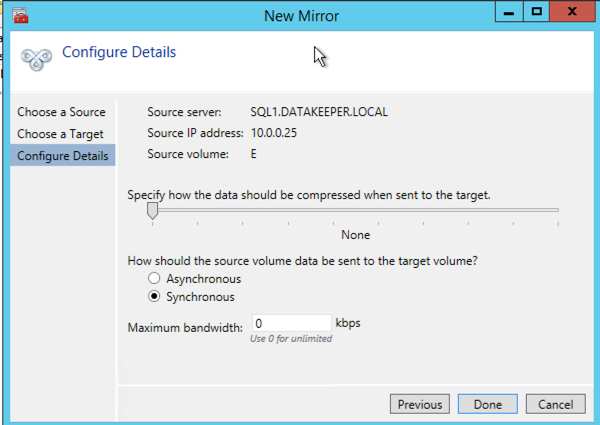
Choose your options. For our purposes where the two VMs are in the same geographic region we will choose synchronous replication. For longer distance replication you will want to use asynchronous and enable some compression.
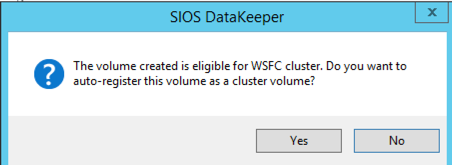
By clicking yes at the last pop-up you will register a new DataKeeper Volume Resource in Available Storage in Failover Clustering.
You will see the new DataKeeper Volume Resource in Available Storage.
Create the File Server Cluster Resource
To create the File Server Cluster Resource we will use Powershell once again rather than the Failover Cluster interface. The reason being is that once again because the virtual machines are configured to use DHCP, the GUI based wizard will not prompt us to enter a cluster IP address and instead will issue a duplicate IP address. To avoid this we will use a simple powershell command to create the FIle Server Cluster Resource and specify the IP Address
Make note of the IP address you specify here. It must be a unique IP address on your network. We will use this same IP address later when we create our Internal Load Balancer.
Create the Internal Load Balancer
Here is where failover clustering in Azure is different than traditional infrastructures. The Azure network stack does not support gratuitous ARPS, so clients cannot connect directly to the cluster IP address. Instead, clients connect to an internal load balancer and are redirected to the active cluster node. What we need to do is create an internal load balancer. This can all be done through the Azure Portal as shown below.
You can use an Public Load Balancer if your client connects over the public internet, but assuming your clients reside in the same vNet, we will create an Internal Load Balancer. The important thing to take note of here is that the Virtual Network is the same as the network where your cluster nodes reside. Also, the Private IP address that you specify will be EXACTLY the same as the address you used to create the File Server Cluster Resource. Also, because we are using Availability Zones we will be creating a Zone Redundant Standard Load Balancer as shown in the picture below.
After the Internal Load Balancer (ILB) is created, you will need to edit it. The first thing we will do is to add a backend pool. Through this process you will choose the two cluster nodes.
The next thing we will do is add a Probe. The probe we add will probe Port 59999. This probe determines which node is active in our cluster.
And then finally, we need a load balancing rule to redirect the SMB traffic, TCP port 445 The important thing to notice in the screenshot below is the Direct Server Return is Enabled. Make sure you make that change.
Fix the File Server IP Resource
The final step in the configuration is to run the following PowerShell script on one of your cluster nodes. This will allow the Cluster IP Address to respond to the ILB probes and ensure that there is no IP address conflict between the Cluster IP Address and the ILB. Please take note; you will need to edit this script to fit your environment. The subnet mask is set to 255.255.255.255, this is not a mistake, leave it as is. This creates a host specific route to avoid IP address conflicts with the ILB.
# Define variables
$ClusterNetworkName = “”
# the cluster network name (Use Get-ClusterNetwork on Windows Server 2012 of higher to find the name)
$IPResourceName = “”
# the IP Address resource name
$ILBIP = “”
# the IP Address of the Internal Load Balancer (ILB)
Import-Module FailoverClusters
# If you are using Windows Server 2012 or higher:
Get-ClusterResource $IPResourceName | Set-ClusterParameter -Multiple @{Address=$ILBIP;ProbePort=59999;SubnetMask="255.255.255.255";Network=$ClusterNetworkName;EnableDhcp=0}
# If you are using Windows Server 2008 R2 use this:
#cluster res $IPResourceName /priv enabledhcp=0 address=$ILBIP probeport=59999 subnetmask=255.255.255.255
Creating File Shares
You will find that using the File Share Wizard in Failover Cluster Manager does not work. Instead, you will simply create the file shares in Windows Explorer on the active node. Failover clustering automatically picks up those shares and puts them in the cluster.
Note that the”Continuous Availability” option of a file share is not supported in this configuration.
Conclusion
You should now have a functioning File Server Failover Cluster in Azure that spans Availability Zones. If you have ANY problems, please reach out to me on Twitter @daveberm and I will be glad to assist. If you need a DataKeeper evaluation key fill out the form at http://us.sios.com/clustersyourway/cta/14-day-trial and SIOS will send an evaluation key sent out to you.
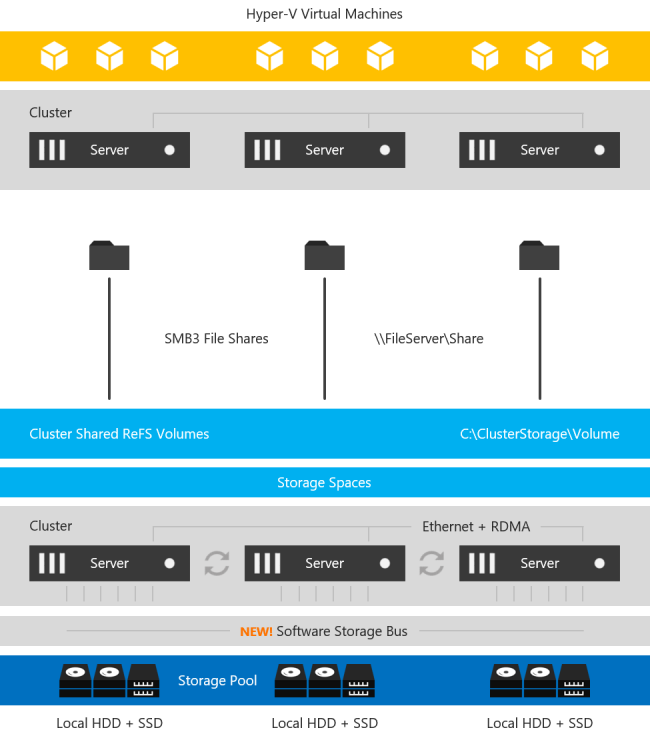
With the introduction of Windows Server 2016 DatacenterEdition a new feature called Storage Spaces Direct (S2D) was introduced. At a very high level, this solution allows you to pool together locally attached storage and present it to the cluster as a CSV for use in a Scale Out File Server, which can then be accessed over SMB 3 and used to hold cluster data such as Hyper-V VMDK files. This can also be configured in a hyper-converged (HCI) fashion such that the application and data can all run on the same set of servers. This is a grossly over-simplified description, but for details, you will want to look here.
The main use case targeted is hyper-converged infrastructure for Hyper-V deployments. However, there are other use cases, including leveraging this SMB storage to store SQL Server Data to be used in a SQL Server Failover Cluster Instance
Why would anyone want to do that? Well, for starters you can now build a highly available 2-node SQL Server Failover Cluster Instance (FCI) with SQL Server Standard Edition, without the need for shared storage. Previously, if you wanted HA without a SAN you pretty much were driven to buy SQL Server Enterprise Edition and make use of Always On Availability Groups or purchase SIOS DataKeeper and leverage the 3rd party solution which lets you build SANless clusters with any version of Windows or SQL Server. SQL Server Enterprise Edition can really drive up the cost of your project, especially if you were only buying it for the Availability Groups feature.
In addition to the cost associated with Availability Groups, there are a number of other technical reasons why you might prefer a Failover Cluster over an AG. Application compatibility, instance vs. database level protection, large number of databases, DTC support, trained staff, etc., are just some of the technical reasons why you may want to stick with a Failover Cluster Instance.
Microsoft lists both the SIOS DataKeeper solution and the S2D solution as two of the supported solutions for SQL Server FCI in their documentation here.
When comparing the two solutions, you have to take into account that SIOS has been allowing you to build SANless Clusters since 1999, while the S2D solution is still in its infancy. Having said that, there are bound to be some areas where S2D has some catching up to do, or simply features that they will never support simply due to the limitations with the technology.
Have a look at the following table for an overview of some of the things you should consider before you choose your SANless cluster solution.
If we go through this chart, we see that SIOS DataKeeper clearly has some significant advantages. For one, DataKeeper supports a much wider range of platforms, going all the way back to Windows Server 2008 R2 and SQL Server 2008 R2. The S2D solution only supports the latest releases of Windows and SQL Server 2016/2017. S2D also requires the Datacenter Edition of Windows, which can add significantly to the cost of your deployment. In addition, SIOS delivers the ONLY HA/DR solution for SQL Server on Linux that works both on-prem and in the cloud.
I’ve been talking to a lot of customers recently who are reporting some performance issues with S2D. When I tested S2D vs. DataKeeper about a year ago I didn’t see any significant differences in performance, but I did see S2D used about 2x the amount of CPU resources under the same load. This probably has to do with the high hardware requirements associated with S2D such as RDMA enabled networking and available Flash Storage, typically only available in the most expensive cloud based images.
“We recommend the I3 instance size because it satisfies the S2D hardware requirements and includes the largest and fastest instance store devices available.”
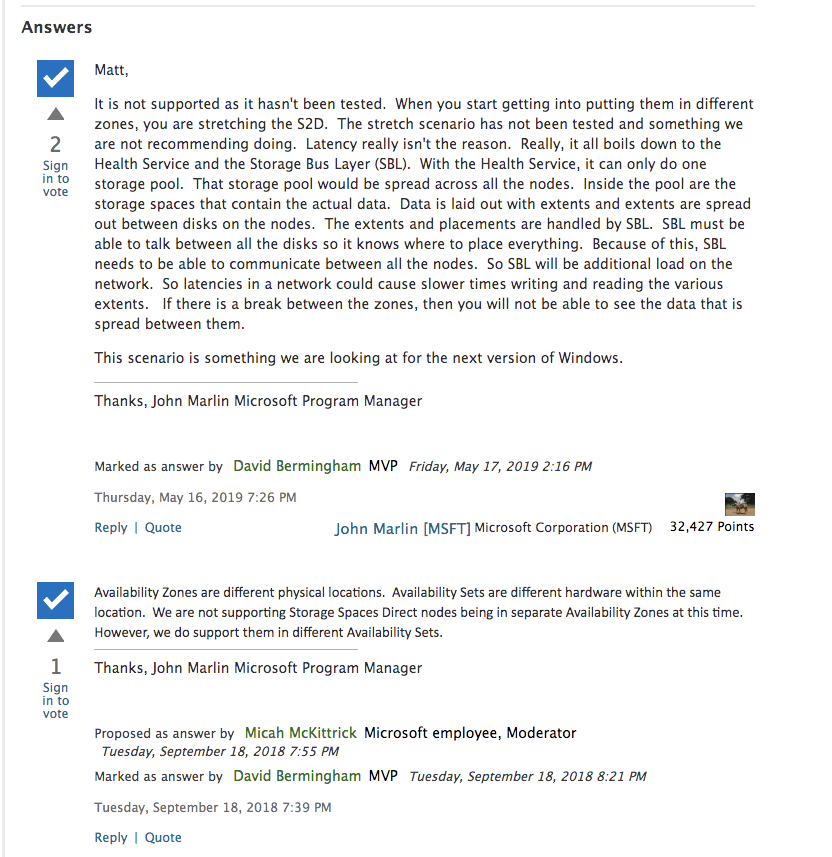
But beyond the cost and platform limitations, I think the most glaring gap comes when we start to consider that S2D does not support Availability Zones or disaster recovery configurations such as multi-site clusters or Azure Site Recovery (ASR). Allan Hirt, SQL Server Cluster guru and fellow Microsoft Cloud and Datacenter Management MVP, recently posted about this S2D limitation. In his article Revisiting Storage Spaces Direct and SQL Server FCIs Allan points out that due to the lack of support for stretching S2D clusters across sites or including an S2D based cluster as a leg in an Always On Availability Group, the best option for DR in the S2D scenario is log shipping! This even includes replicating across Availability Zones in either Azure or AWS.
Microsoft does not make it clear in their documentation, but Microsoft’s own PM for High Availability and Storage makes it perfectly clear in the Microsoft forums.
AWS also documents S2D’s lack of Availability Zone support…
“Each cluster node must be deployed in a different subnet. This architecture will be deployed into a single availability zone because Microsoft does not currently support stretch cluster with Storage Spaces Direct. ” – AWS Documentation on S2D
Deploying S2D cluster nodes within the same Availability Zone defeats the purpose of failover clustering and the deployment does not qualify for the AWS 99.99% SLA. Even if you wanted to deploy S2D in a single Availability Zone the deployment becomes even more complicated because it is recommended that you deploy at least three cluster nodes and each node must reside in its own subnet due to some AWS networking restrictions that requires each cluster node reside in a different subnet. S2D was never designed to run in different subnets, which further complicates the solution in terms of client redirection.
“One item to note is that if you are familiar with Failover Clusters in the past, stretch clusters have been a very popular option over the years. There was a bit of a design change with the hyper-converged solution and it is based on resiliency. If you lose two nodes in a hyper-converged cluster, the entire cluster will go down. With this being the case, in a hyper-converged environment, the stretch scenario is not supported.”
In contrast, the SIOS DataKeeper solution fully supports Always On Availability Groups, and better yet – it can allow you to stretch your FCI across sites to give you the best HA/DR solution you could hope to achieve in terms of RTO/RPO. DataKeeper supports Availability Zones and DR configurations that cross cloud regions. In an Azure environment, DataKeeper also support Azure Site Recovery (ASR), giving you even more options for disaster recovery.
Further complicating any S2D deployment in AWS is the reliance on “local instance store” storage, AKA, non-persistent ephemeral disks.
“The best performance for storage can be achieved using I3 instances because they provide local instance store with NVMe and high network performance”
Reliance on ephemeral storage puts your data at risk any time a disk rebuilds, which can happen at any time, but always happens when an instance is stopped. If a disk is lost and a second disk is lost before the first disk rebuilds you are looking at complete data loss and a restore from backup. If someone accidentally stops all the nodes in your cluster your data will be lost! Even if you take care to only stop one node at a time if you are not paying attention and waiting for a disk to complete a rebuild after you stop the second node you will also experience complete data loss!
The SIOS DataKeeper solution is much more lenient. It supports any locally attached storage and as long as the hardware passes cluster validation, it is a supported cluster configuration. The block level replication solution has been working great ever since 1 Gbps was considered a fast LAN and a T1 WAN connection was considered a luxury.
SANless clustering is particularly interesting for cloud deployments. The cloud does not offer traditional shared storage options for clusters. So for users in the middle of a “lift and shift” to the cloud that want to take their clusters with them they must look at alternate storage solutions. For cloud deployments, SIOS is certified for Azure, AWS and Google and available in the relevant cloud marketplace. While there doesn’t appear to be anything blocking deployment of S2D based clusters in AWS or Google, there is a conspicuous lack of documentation or supportability statements from Microsoft for those platforms.
SIOS DataKeeper has been doing this since 1999. SIOS has heard all the feature requests, uncovered all the bugs, and has a rock solid solution for SANless clusters that is time tested and proven. While Microsoft S2D is a promising technology, as a 1st generation product I would wait until the dust settles and some of the feature gap closes before I would consider it for my business critical applications.
Many people have found themselves settling for SQL Server Standard Edition due to the cost of SQL Server Enterprise Edition. SQL Server Standard Edition has many of the same features, but has a few limitations. One limitation is that it does not support AlwaysOn Availability Groups. Also, it only supports two nodes in a cluster. With Database Mirroring being deprecated and only supporting synchronous replication in Standard Edition, you really have limited disaster recovery options.
One of those options is SIOS DataKeeper Cluster Edition. DataKeeper will work with your existing shared storage cluster and allow you to extend it to a 3rd node using either synchronous or asynchronous replication. If you are using SQL Server Enterprise you can simply add that 3rd node as another cluster member and you have a true multisite cluster. However, since we are talking about SQL Server Standard Edition you can’t add a 3rd node directly to the cluster. The good news is that DataKeeper will allow you to replicate data to a 3rd node so your data is protected.
Recovery in the event of a disaster simply means you are going to use DataKeeper to bring that 3rd node online as the source of the mirror and then use SQL Server Management Studio to mount the databases that are on the replicated volumes. You clients will also need to be redirected to this 3rd node, but it is a very cost effective solution with an excellent RPO and reasonable RTO.
The SIOS documentation talks about how to do this, but I have summarized the steps recently for one of my clients.
Configuration
Stop the SQL Resource
Remove the Physical Disk Resource From The SQL Cluster Resource
Remove the Physical Disk from Available Storage
Online Physical Disk on SECONDARY server, add the drive letter (if not there)
Run emcmd . setconfiguration <drive letter> 256
and Reboot Secondary Server. This will cause the SECONDARY server to block access to the E drive which is important because you don’t want two servers having access to the E drive at the same time if you can avoid it.
Online the disk on PRIMARY server
Add the Drive letter if needed
Create a DataKeeper Mirror from Primary to DR
You may have to wait a minute for the E drive to appear available in the DataKeeper Server Overview Report on all the servers before you can create the mirror properly. If done properly you will create a mirror from PRIMARY to DR and as part of that process DataKeeper will ask you about the SECONDARY server which shares the volume you are replicating.
In the event of a disaster….
On DR Node
Run EMCMD . switchovervolume <drive letter>
The first time make sure the SQL Service account has read/write access to all data and log files. You WILL have to explicitly grant this access the very first time you try to mount the databases.
Use SQL Management Studio to mount the databases
Redirect all clients to the server in the DR site, or better yet have the applications that reside in the DR site pre-configured to point to the SQL Server instance in the DR site.
After disaster is over
Power the servers (PRIMAY, SECONDARY) in the main site back on
Wait for mirror to reach mirroring state
Determine which node was previous source (run PowerShell as an administrator)
get-clusterresource -Name “<DataKeeper Volume Resource name>” | get-clusterparameter
Make sure no DataKeeper Volume Resources are online in the cluster
Start the DataKeeper GUI on one cluster node. Resolve any split brain conditions (most likely there are none) ensuring the DR node is selected as the source during any split-brain recovery procedures
On the node that was reported as the previous source run EMCMD . switchovervolume <drive letter>
Bring SQL Server online in Failover Cluster Manager
The above steps assume you have SIOS DataKeeper Cluster Edition installed on all three servers (PRIMARY, SECONDARY, DR) and that PRIMARY and SECONDARY are a two node shared storage cluster and you are replicating data to DR which is just a standalone SQL Server instance (not part of the cluster) with just local attached storage. The DR Server will have a volume(s) that is the same size and drive letter as the shared cluster volume(s). This works rather well and will even let you replicate to a target that is in the cloud if you don’t have your own DR site configured.
You can also build the same configuration using all replicated storage if you want to eliminate the SAN completely.
There was an interesting discussion happening today in the Twitterverse. Basically, someone asked the question “Has anyone set up a SQL Server AlwaysOn Failover Cluster Instance in Azure?” The ensuing conversation involved some well respect SQL Server experts which led to the following question, “Why would you want to build a SQL Server AlwaysOn Failover Cluster instance in the cloud?”
That question could be interpreted in two ways: “Why do you need High Availability in the Cloud” or “Why wouldn’t you use AlwaysOn Availability Groups instead of Failover Cluster Instances?”
Let’s address each question one at a time.
Question 1 – Why do you need High Availability in the Azure Cloud?
You might think that just because you host your SQL Server instance in Azure, that you are covered by their 99.95% uptime SLA. If you think that, you would be wrong. In order to take advantage of the 99.95% SLA you have to have at least two instances of SQL running in an Availability Set. With a single instance of SQL running you can definitely expect that there will minimally be downtime during maintenance periods, but you are also susceptible to unplanned failures.
Two instances of SQL Server cannot generally be load balanced, so you have to implement some sort of mechanism to keep the servers in sync and to ensure that if there is a problem with one of the servers, the other server will be able to continue to service the requests. High Availability solutions like AlwaysOn Availability Groups, AlwaysOn Failover Cluster Instances and even the deprecated Database Mirroring can provide high availability for SQL Server in that scenario. Other solutions like log shipping and transactional replication may be able to help keep data synchronized between servers, but they are not typically considered high availability solutions and will not ensure the availability of your SQL Server.
Microsoft does occasionally need to perform maintenance on Azure that could bring down an entire Upgrade Domain and all the instances running in that Upgrade Domain. You don’t have any say on when this will happen, so you need to have a mechanism in place to ensure that if they do have to bring down your primary SQL Server instance, you can expect that your secondary SQL Server instance will take over the workload without missing a beat. All of the high availability solutions mentioned above can ensure that you will continue to run in the event that Microsoft is doing maintenance on the Upgrade Domain of your primary server. Microsoft will only do maintenance on a single Upgrade Domain at a time, ensuring that your secondary server will still be online assuming you put the both in the same Availability Set.
What do you do if YOU want to performance maintenance on your production SQL Server? Maybe you want to install a Service Pack or other hotfix? Without a secondary server to fail over to, you will have to schedule planned downtime. One of the primary benefits of any high availability solution is the ability to do rolling upgrades, minimizing the impact of planned downtime.
Question 2 – Why wouldn’t you use AlwaysOn Availability Groups instead of Failover Cluster Instances?
Save Money! SQL Server AlwaysOn Availability Groups requires Enterprise Edition of SQL Server. Why not save money and deploy SQL Server Standard Edition and build a simple 2-node Failover Cluster Instance? Unless you need Enterprise Edition for some other reason, this is a no brainer.
Protect the ENTIRE SQL Server instance. AlwaysOn Availability Groups only protects user defined databases; you cannot protect the System and MSDB databases. If you build a Failover Cluster Instance instead, you are protecting the ENTIRE instance, including the System and MSDB databases.
Ease Administration. In Azure, you are limited to just on client listener. This limits you to just one Availability Group. In contrast, with a Failover Cluster Instance one client listener is all you need, so there is no limitation.
Worker Thread Exhaustion. With AlwaysOn AG you have to keep an eye on the available worker threads. The available worker threads limit the number of databases you can protect with AlwaysOn AG. In contrast, AlwaysOn Failover Clustering with DataKeeper block level replication does not consume more resources for each database you add, meaning you can scale to protect hundreds of databases without the additional overhead associated with AlwaysOn AG.
Distribute Transaction Support. AlwaysOn AG does not support distributed transactions (DTC), so if your application requires DTC support you are going to have to look at an AlwaysOn Failover Cluster Instance instead.
Support of Other Replication Technologies. If you plan on setting up Peer to Peer replication between two databases protected by AlwaysOn AG you can forget about it. In fact, there are many restrictions you have to be aware of once you deploy AlwaysOn Availability Groups. AlwaysOn FCI’s do not have any of those restrictions.
Knowing what you know above, shouldn’t the question really be “Why would I want to implement AlwaysOn AG in the Cloud when I can have a much more robust and inexpensive solution building an AlwaysOn Failover Cluster instance?”
In case you missed it, I held this in depth webinar on cluster quorums. In 30 minutes I go over everything you need to know about quorums, from node majority through Cloud Witness and everything in between. If you have additional questions about quorums post them as a comment on this article and I will be glad to help.
If you are new to clustering or just new to clustering in Windows Server 2012 R2 this is class for you. Symon Perriman (@SymonPerriman), 5nine Software Vice President of Business Development and Elden Christensen, Microsoft Principal Program Manager Lead, live and breathe failover clustering. You can’t ask for any better instructors. Stop what you are doing and watch this RIGHT NOW!


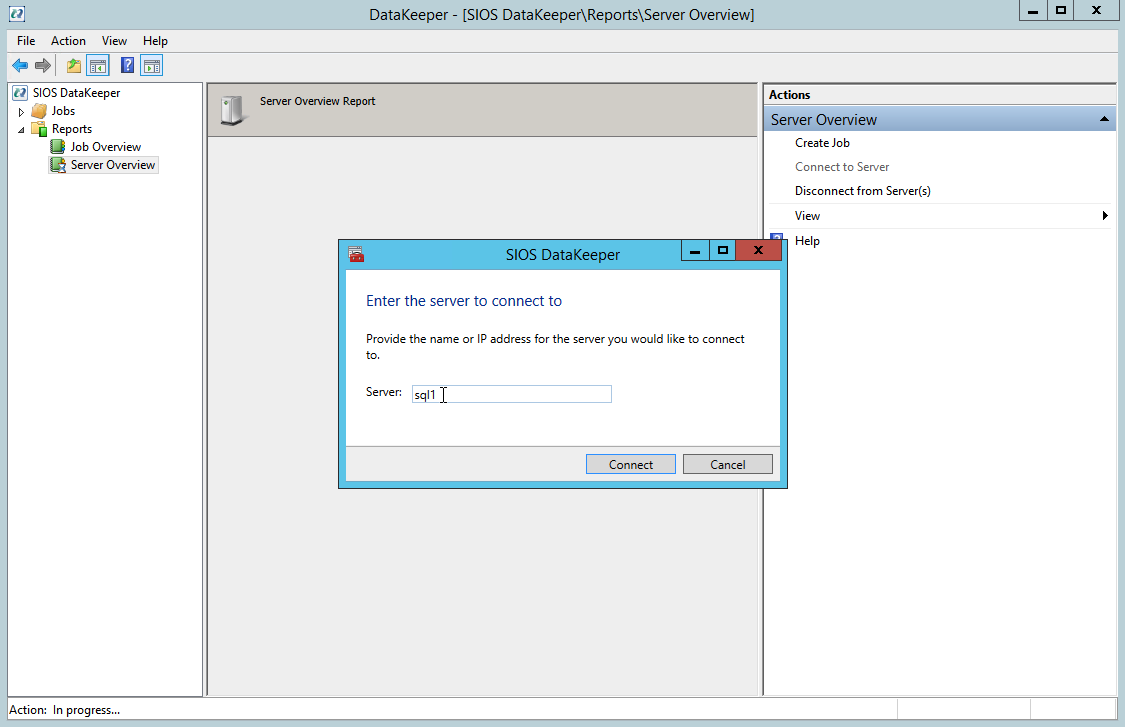





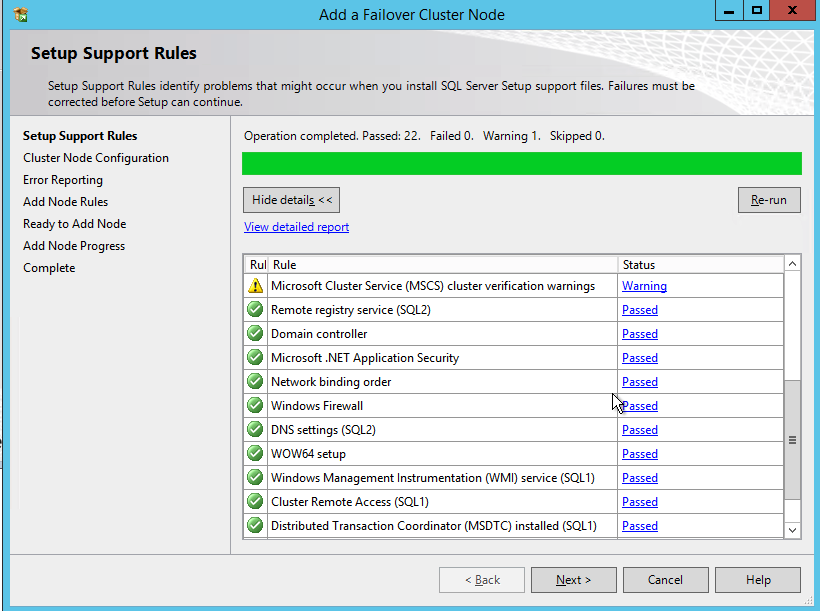




 Connect to SQL1
Connect to SQL1