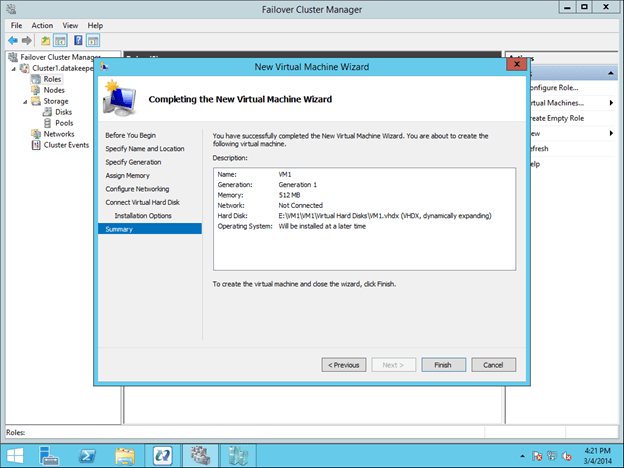
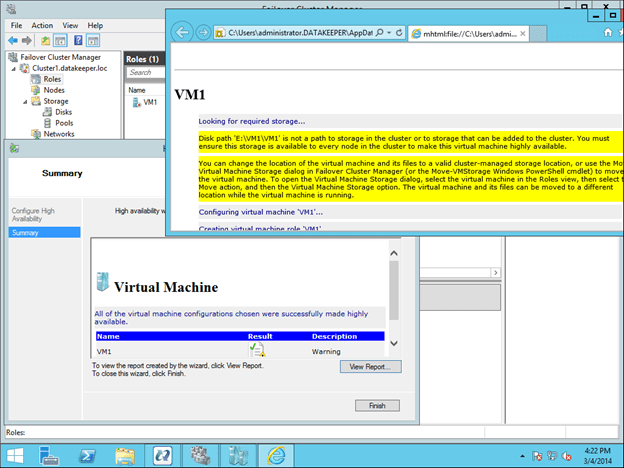
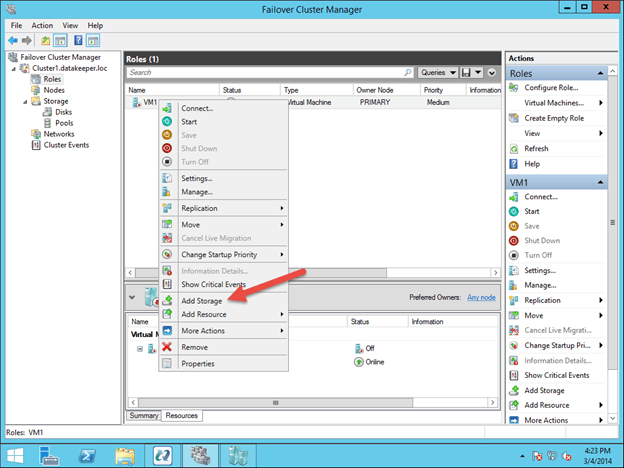
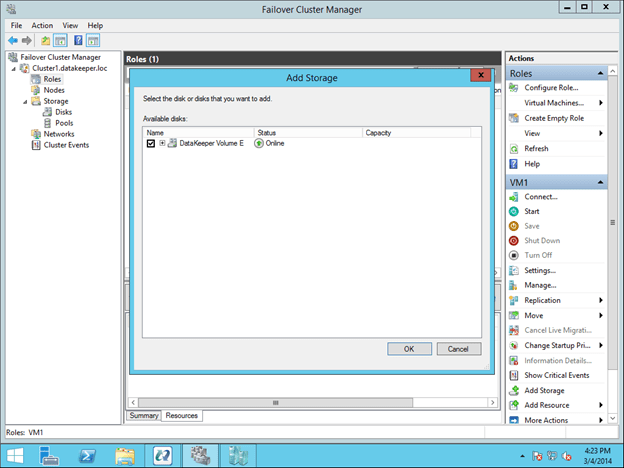
Understanding the Windows Server Failover Cluster Quorum in Windows Server 2012 R2
Before we get started with all the great new cluster quorum features in Windows Server 2012 R2, we should take a moment and understand what the quorum does and how we got to where we are today. Rob Hindman describes quorum best in his blog post…
“The quorum configuration in a failover cluster determines the number of failures that the cluster can sustain while still remaining online.”
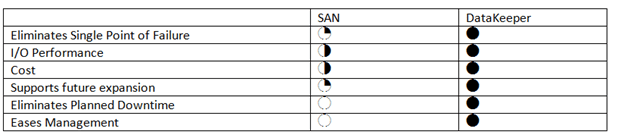
Prior to Windows Server 2003, there was only one quorum type, Disk Only. This quorum type is still available today, but is not recommended as the quorum disk is a single point of failure. In Windows Server 2003 Microsoft introduce the Majority Node Set (MNS) quorum. This was an improvement as it eliminated the disk only quorum as a single point of failure in the cluster. However, it did have its limitations. As implied in its name, Majority Node Set must have a majority of nodes to form a quorum and stay online, so this quorum model is not ideal for a two node cluster where the failure of one node would only leave one node remaining. One out of two is not a majority, so the remaining node would go offline.
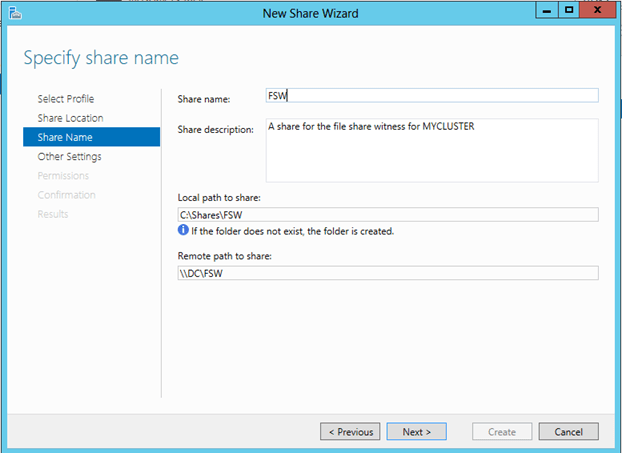
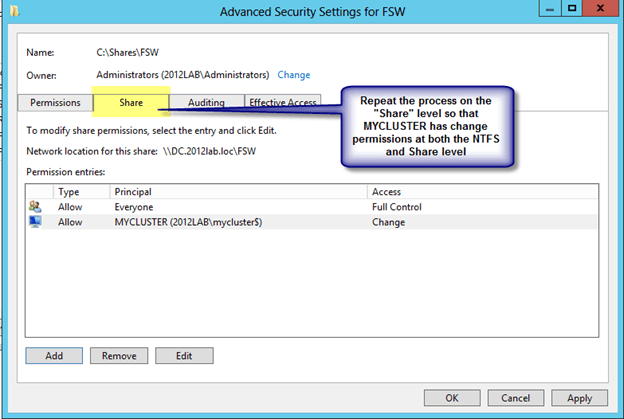
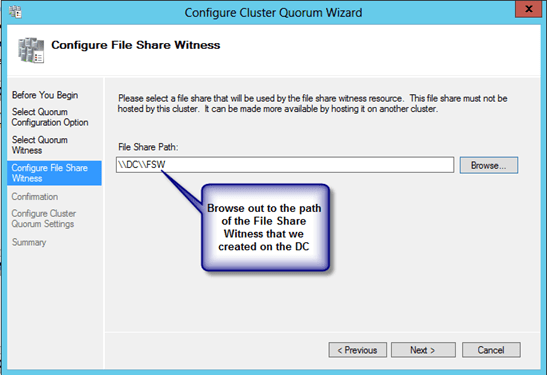
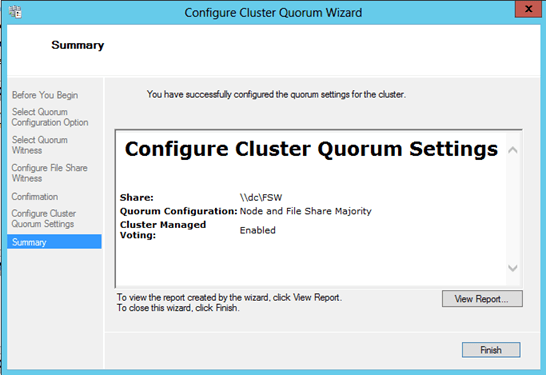
Microsoft introduced a hotfix that allowed for the creation of a File Share Witness (FSW) on Windows Server 2003 SP1 and 2003 R2 clusters. Essentially the FSW is a simple file share on another server that is given a vote in a MNS cluster. The driving force behind this innovation was Exchange Server 2007 Continuous Cluster Replication (CCR), which allowed for clustering without shared storage. Of course without shared storage a Disk Only Quorum was not an option and effective MNS clusters would require three or more cluster nodes, hence, the introduction of the FSW to support two node Exchange CCR clusters.
Windows Server 2008 saw the introduction of a new witness type, Disk Witness. Unlike the old Disk Only quorum type, the Disk Witness allows the users to configure a small partition on a shared disk that acts as a vote in the cluster, similar to that of the FSW. However, the Disk Witness is preferable to the FSW because it keeps a copy of the cluster database and eliminates the possibility of “partition in time”. If you’d like to read more about partition in time, I suggest you read the File Share Witness vs. Disk Witness for local clusters.
Windows Server 2012 continued to improve upon quorum options. It is my belief that many of these new features were driven by two forces: Hyper-V and SQL Server AlwaysOn Availability Groups. With Hyper-V we began to see clusters that contained many more nodes than we have typically seen in the past. In a majority node set, as soon as you lose a majority of your votes, the remaining nodes go offline. So for example, if you have a Hyper-V cluster with seven nodes, if you were to lose four of those nodes the remaining nodes would go offline, even though there are three nodes remaining. This might not be exactly what you want to happen. So in Windows Server 2012, Microsoft introduced Dynamic Quorum.
Dynamic Quorum does what its name implies, it adjust the quorum dynamically. So in the scenario described about, assuming I didn’t lose all four servers at the same time, as servers in the cluster went offline, the number of votes in the quorum would adjust dynamically. When node one went offline, I would then in theory have a six node cluster. When node two went offline, I would then have a five node cluster, and so on. In reality, if I continued to lose cluster nodes one by one, I could go all the way down to a two node cluster and still remain online. And, if I had configured a witness (Disk or File Share) I could actually go all the way down to a single node and still remain online.
Read more at….