One of the most exciting new features in Windows Server 10 announced by Microsoft is Storage Replicas. It is described by Microsoft here: http://technet.microsoft.com/en-us/library/dn765475.aspx#BKMK_SR
“Storage Replica (SR) is a new feature that enables storage-agnostic, block-level, synchronous replication between servers for disaster recovery, as well as stretching of a failover cluster for high availability. Synchronous replication enables mirroring of data in physical sites with crash-consistent volumes ensuring zero data loss at the file system level. Asynchronous replication allows site extension beyond metropolitan ranges with the possibility of data loss.
What value does this change add?
Storage Replication enables you to do the following:
Provide an all-Microsoft disaster recovery solution for planned and unplanned outages of mission-critical workloads.
Use SMB3 transport with proven reliability, scalability, and performance.
Stretch clusters to metropolitan distances.
Use Microsoft software end to end for storage and clustering, such as Hyper-V, Storage Replica, Storage Spaces, Cluster, Scale-Out File Server, SMB3, Deduplication, and ReFS/NTFS.
Help reduce cost and complexity as follows:
Hardware agnostic, with no requirement to immediately abandon legacy storage such as SANs.
Allows commodity storage and networking technologies.
Features ease of graphical management for individual nodes and clusters through Failover Cluster Manager and Microsoft Azure Site Recovery.
Includes comprehensive, large-scale scripting options through Windows PowerShell.
Helps reduce downtime, and increase reliability and productivity intrinsic to Windows.
Provide supportability, performance metrics, and diagnostic capabilities.”
They mention a lot of use cases “… Hyper-V, Storage Replica, Storage Spaces, Cluster, Scale-Out File Server, SMB3, Deduplication, and ReFS/NTFS”. I’m not even sure what they mean by listing technologies such as ReFS/NTFS, Deduplication, SMB3, Storage Replica, Storage Spaces. These seem more like features rather than use cases, which I’m going to assume they are.
But let’s look at some of the other use cases they mentioned: Hyper-V, Cluster, Scale-out-File Server. I can easily imagine how Storage Replica is going to enhance these use cases by enabling shared nothing Scale-Out-File Servers and multisite clusters, including Hyper-V, SQL Server, File Servers, etc. In some cases it can also enable SANLess local area network clusters, allowing clusters to be built without requiring a shared Physical Disk resource.
In my first look at this solution I decided to focus on what I know and love, failover clusters. To keep things easy I decided I was going to focus on building a simple two node traditional file server (not scale out file server). I decided I was going to start with three fresh VMs in an entirely pure Windows Server 10 domain. It was easy enough to download the ISO’s and the install onto my 3 VMs went surpringly fast. Promoting a DC was a pretty similar experience to 2012 R2, though I think it was made a little more obvious that you have to actually run the DCPromo after the AD feature was installed.
I got my domain installed and my basic two node cluster with no resources built without a problem. I used VMware Fusion as my Hypervisor since it supports nested Hypervisors (a feature sorely lacking in Hyper-V for testing and demo by the way). I added a few additional VMDK files to each VM in my cluster and formatted them as E: and F: on each VM, figuring these would be my replica volumes. I had not defined resources yet and the cluster had no shared storage. Perfect, ready to start configuring Storage Replica!
So I fire up the Failover Cluster Manager and start poking around to see how I could start the replication process. There was absolutely nothing in the UI that I could find that said, Replica, Replication or anything even close to that. Because the documentation hadn’t shipped and the bits had only become available a few hours ago I was on my own to figure it out, despite my desperate Twitter searches for a how to blog. No problem I said, I’m a cluster MVP and my specialty is replication and multisite clusters so I’ll figure this out.
After a little searching I find that there is a new feature called Windows Volume Replication.
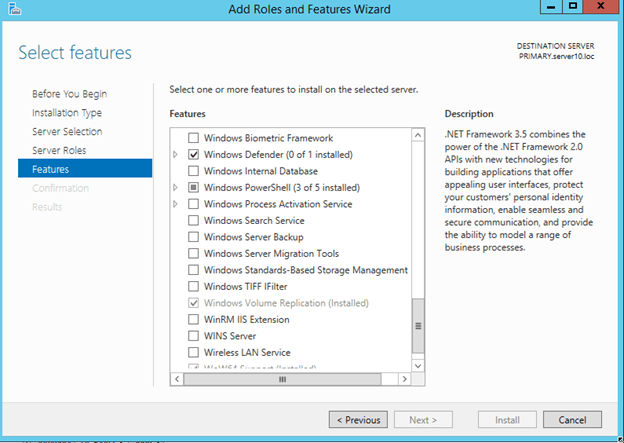
Great, so I enable that on both nodes thinking this is going to be great, but still nothing is jumping out at me in the Windows Failover Cluster UI that says “Configure Replica”. Scratching my head some more and trying to reach out to a few smart people I still had no clue. Then it dawned on me…”maybe it only supports Cluster Disk?” Now the feature announcement says “supports commodity storage”. To me that means any old hard drive in my PC or in this case the attached virtual disk on my VMs. As it turns out, I was correct; the disk has to appear in the cluster as a Physical Disk Resource in Available Storage.
OK, not the greatest requirement, but I continued plugging away. To get some disks that could be added as Physical Disk Resources attached to my VMs I enabled the iSCSI target role on my DC and create two iSCSI Virtual Disks for each of my VMs. Now remember, this is not like a regular cluster so each of these virtual disks were only assigned to one VM, they were not shared.
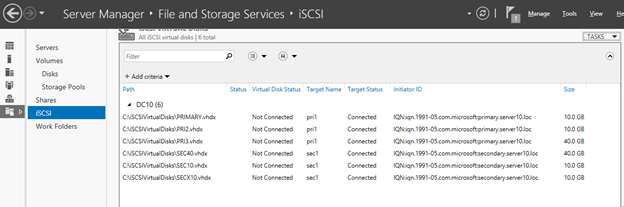
One each VM I used the iSCSI initiator to connect to these disks, initialized, onlined and formatted them. I then used Failover Cluster Manager to add them to the cluster.
Finally, I see some new options for replication.

I still struggled for a while to get the Replication enable button to even become selectable.
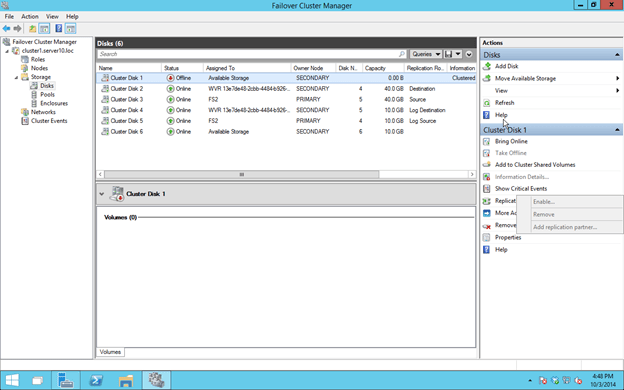
Here are the IMPORT things you need to know to get this show on the road:
- The Disk must be Physical Dis Resources in the cluster. This means they must support SCSI3 reservations and must pass cluster validation.
- The Disk must be GPT, not MBR
- Each Disk you want to replicate must have an associated Disk to be used for the “Log File”. I assume this is where they queue data when replication is interrupted or in asynchronous mirrors where the data can be slightly behind
- You must add the disk (just the data disk, not the log disk) to a cluster resource BEFORE your can enable replication. You cannot enable replication on a disk that is sitting in Available Storage
- Your Source and Target Servers must have the same size disks and volume letters
Once you do that you will finally be able to enable Replication.
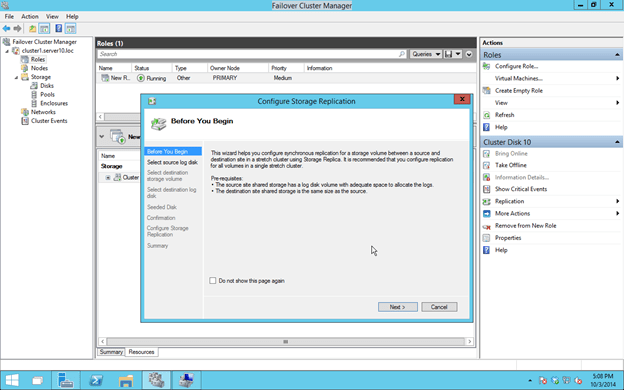
Like I said, you will need to choose a source log disk that needs to be in available storage. Microsoft recommends a SSD disks. I don’t know how big it should be. I assume the bigger it is the longer replication can be interrupted before you consume all the space and break your mirror.
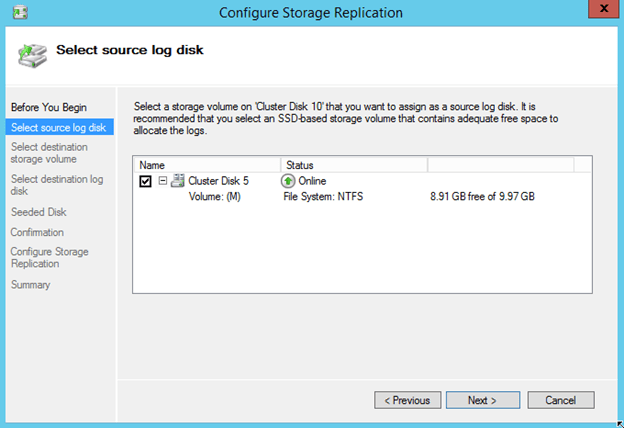
Next step is to choose the Disk on your target server. If you get a message like “No Storage Available” you probably need to move “Available Storage” so that the target disk is Online on the Secondary server.
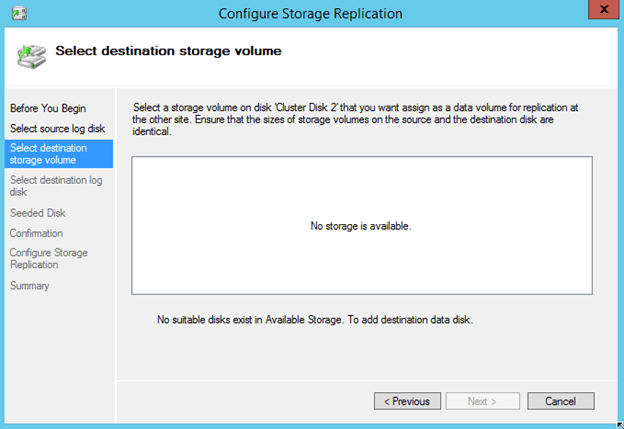
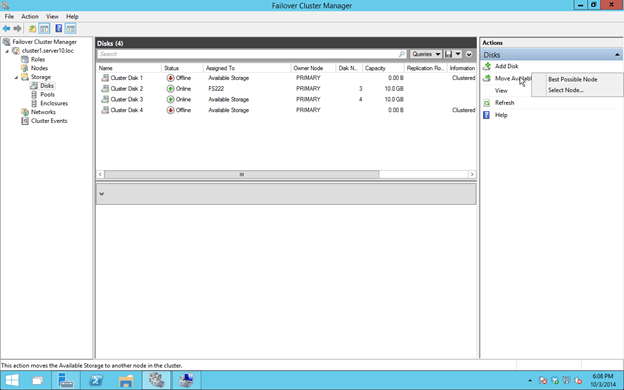
Make not that in the Technical Preview the Move Available Storage seems to be broken if you choose “Select Node”. However, if you choose “Best Possible Node” things seem to work and Available Storage will come online on the SECONDARY server.
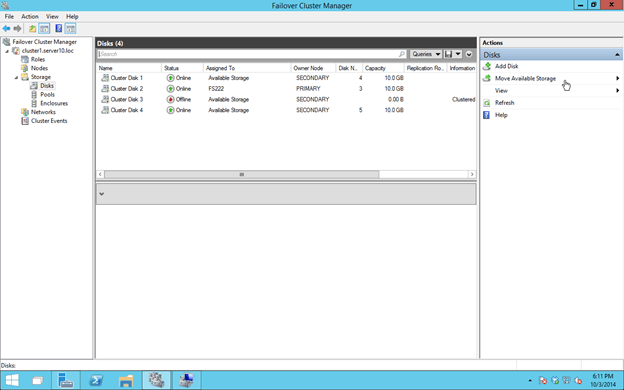
Now all Available Storage should be online on the SECONDARY server.
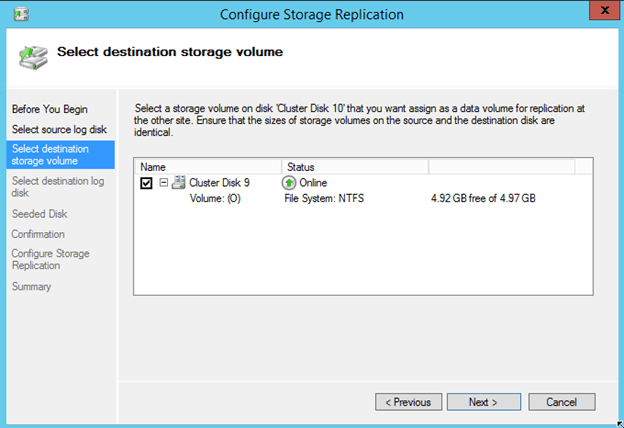
And a disk for the target’s log file
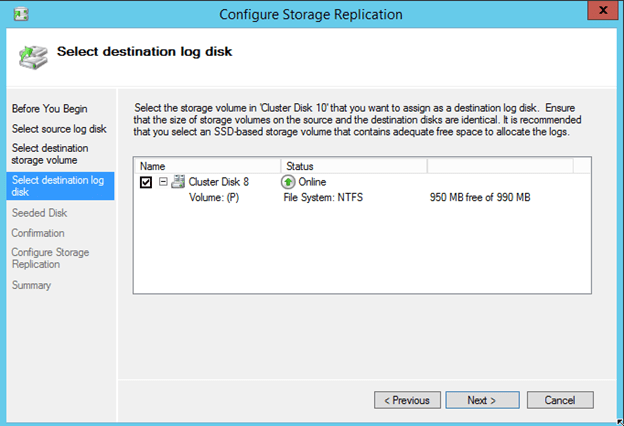
This looks like a nice feature, especially for WAN replication. Apparently you can seed to destination disk, avoiding a full sync over the WAN.
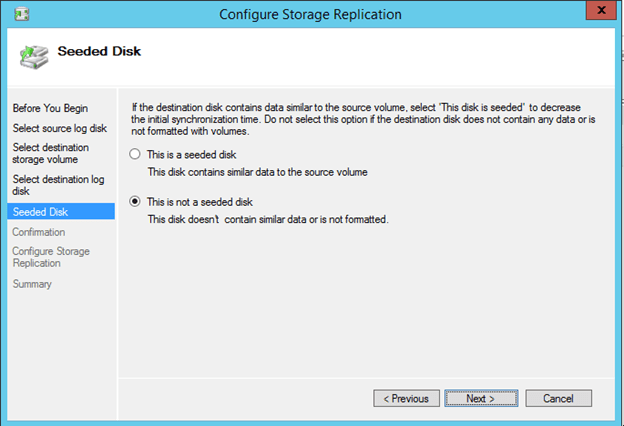
The next screen just confirms everything…
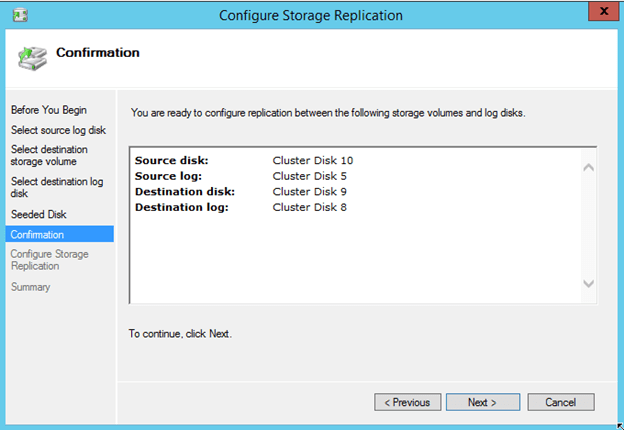
When all is said and done, your cluster should look like this. You’ll probably notice that the Replication status displays “Unknown”. I’m assuming that is a bug that will be addressed later.
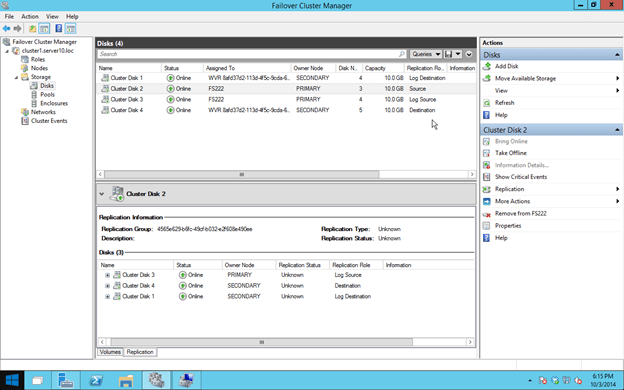
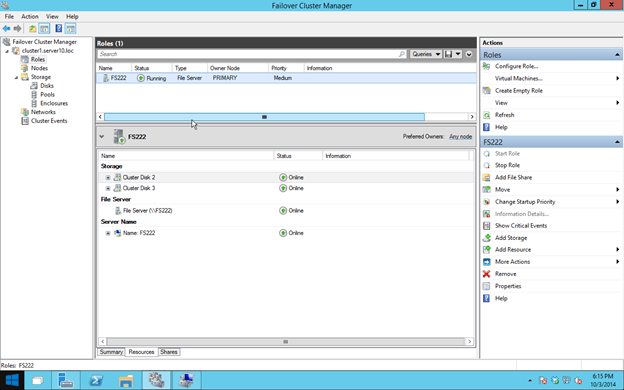
The other bug that I noticed is that the File Share creation wizard that is available via the Failover Cluster Manager doesn’t seem to work. It just closes unexpectedly after you launch it. However, you can create shares on the active node using File Manager and it will automatically be added to the cluster.
Some basic testing seems to indicate that it works fine. Just be careful that you know which of your volumes are the replicated data volumes and which ones are the log volumes. Data written to the log files is not replicated, so if you make a mistake (like I did) you may think replication is not working.
And finally, after all this trial and error I come to find that Microsoft has started to post at least a few pointers on how to make this work. Check out the requirements in this post from Ned Pyle, Storage Replica PM. http://social.technet.microsoft.com/Forums/windowsserver/en-US/f843291f-6dd8-4a78-be17-ef92262c158d/getting-started-with-windows-volume-replication?forum=WinServerPreview&prof=required
My thoughts…
I reserve my thoughts until I have some more time to play with this feature…

Excellent guide! Thanks for posting it.
A Windows Server Technical Preview Storage Replica Guide from Microsoft is now available for download at http://download.microsoft.com/download/8/8/F/88FB4BBF-8ADC-41E0-A64F-489CEEF5218E/Windows%20Server%20Technical%20Preview%20Storage%20Replica%20Guide.docx